|
|
2018-11-01 16:07技術/谷歌/大腦
夏乙 曉查 乾明 問耕 發自 凹非寺
BERT終於來了!今天,谷歌研究團隊終於在GitHub上發布了萬眾期待的BERT。
代碼放出不到一天,就已經在GitHub上獲得1500多星。

項目地址:https://github.com/google-research/bert#fine-tuning-with-bert
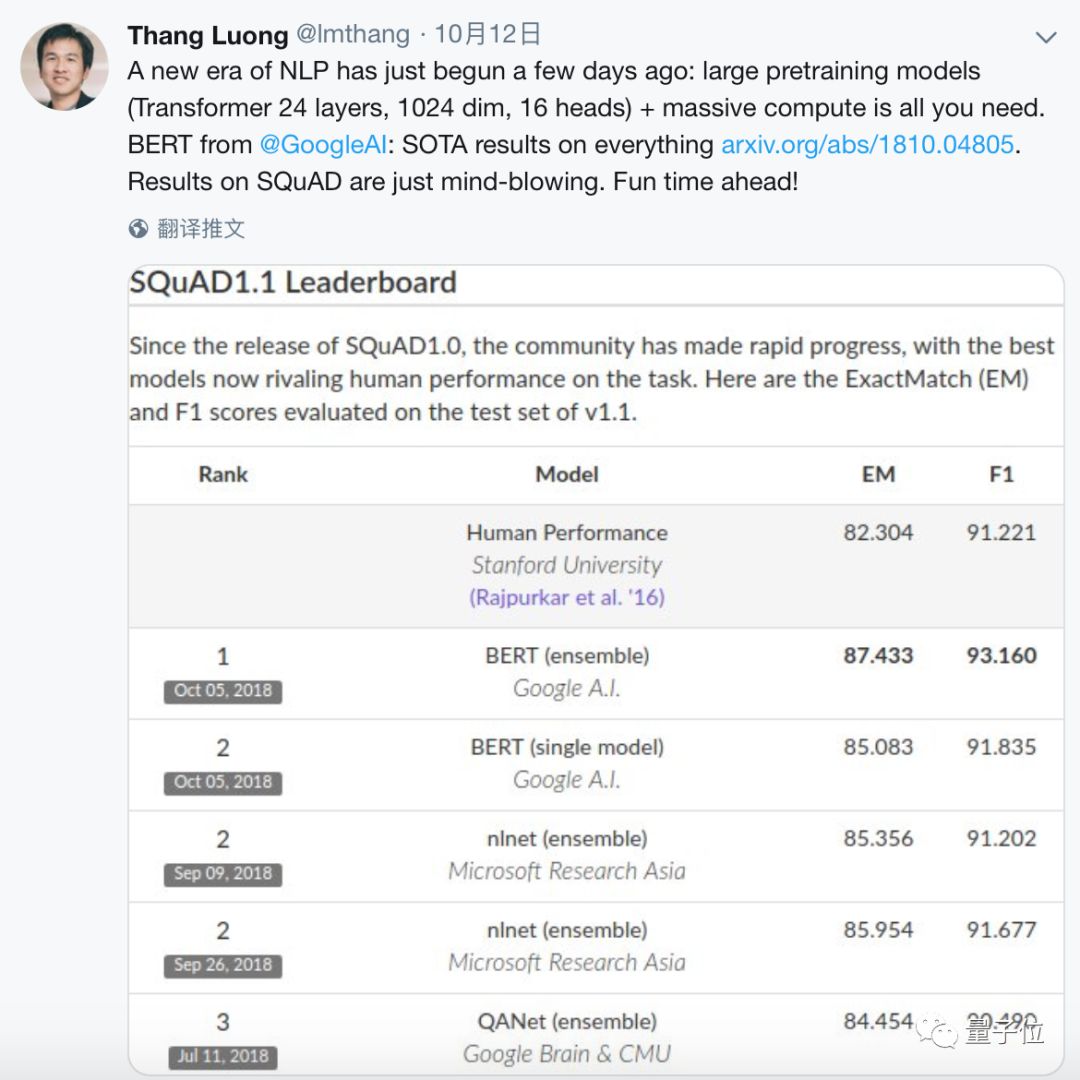
就在半個月前,谷歌才發布這個NLP預訓練模型的論文(https://arxiv.org/abs/1810.04805)。BERT一出現,就技驚四座碾壓了競爭對手,在11項NLP測試中刷新了最高成績,甚至全面超越了人類的表現。
BERT的出現可以說是NLP領域最重大的事件,谷歌團隊的Thang Luong認為BERT標誌著NLP新時代的開始。
BERT是什麼?
BERT全稱Bidirectional Encoder Representations from Transformers,是預訓練語言表示的方法,可以在大型文本語料庫(如維基百科)上訓練通用的「語言理解」模型,然後將該模型用於下游NLP任務,比如機器翻譯、問答。
BERT是第一個無監督的用於預訓練NLP的深度雙向系統。無監督意味著BERT僅使用文本語料庫進行訓練,也就是說網路上有大量多種語言文本數據可供使用。
NLP預訓練的表示也可以是無語境的,也可以是語境關聯的,而且語境表示可以是單向的也可以是雙向的。
諸如word2vec或GloVe之類的無語境模型由辭彙表中的每個單詞生成單個「單詞嵌入」表示,因此像「bank」這樣的單詞會有「銀行」和「河岸」兩種表示。而語境模型則會根據句子中其他單詞來生成每個單詞的表示。
BERT建立在最近的預訓練語境表示工作的基礎上,包括半監督序列學習,生成預訓練,ELMo和ULMFit,但關鍵的是這些模型都是單向或淺雙向的。
這意味著每個單詞僅使用前面(或後面)的單詞進行語境化。例如,在「I made a bank deposit」的句子中,做出「bank」的單向表示可能僅僅基於前文「I made」,而不是後文「deposit」。
前人的一些工作確實結合了來自單獨的前文或者後文模型的表示,但這種方式很「淺」。
而BERT表示「bank」從深度神經網路的最底層開始,同時結合了上下文「I made a…deposit」 ,因此雙向的聯繫很「深」。
BERT使用一種簡單的方法:屏蔽輸入中15%的單詞,通過深度雙向Transformer編碼器運行整個序列,然後預測被屏蔽的單詞。例如:
Input: the man went to the [MASK1] . he bought a [MASK2] of milk.
Labels: [MASK1] = store; [MASK2] = gallon
為了學習句子之間的關係,還訓練一個可以從任何單語語料庫生成的簡單任務:給出兩個句子A和B,讓機器判斷B是A的下一句,還是語料庫中的隨機句子?
Sentence A: the man went to the store .(句子A:男人走進商店)
Sentence B: he bought a gallon of milk .(句子B:他買了一加侖牛奶)
Label: IsNextSentence (是下一句)
Sentence A: the man went to the store .(句子A:男人走進商店)
Sentence B: penguins are flightless .(句子B:企鵝不會飛)
Label: NotNextSentence (不是下一句)
然後,Google在大型語料庫(維基百科和 BookCorpus)上訓練了一個大型模型(12層到24層Transformer),花費了很長時間(100萬升級步驟),這就是BERT。
使用BERT分為兩步:預訓練和微調。
預訓練的代價非常高昂(需要4到16個雲TPU訓練4天),但是每種語言都是訓練一次就夠了。谷歌大腦團隊發布了一些預訓練的模型,目前僅限英語,但不久后也會發布多語言模型。大多數NLP研究人員根本不需要從頭開始訓練他們自己的模型。
與預訓練不同,微調則比較容易。從完全相同的預訓練模型開始,本文中的所有結果只需最多在單個雲TPU上運行1小時,或者在GPU上運行幾小時。例如,目前最先進的單系統SQuAD,在單個雲TPU上訓練大約30分鐘,就能獲得91.0%的Dev F1分數。
BERT的另一個重要特性是,它能適應許多類型的NLP任務。它的論文里就展示了句子級別(如SST-2),句對級別(如MultiNLI),單詞級別(如NER)和小段級別(如SQuAD)的最新結果,幾乎沒有針對特定任務進行修改。
支持漢語嗎?
目前放出的預訓練模型是英語的,不過,谷歌大腦團隊打算11月底之前放出經更多語言預訓練的多語種模型。
更多語言究竟包括哪些?官方沒有給出準確信息,不過BERT一作Jacob Devlin回應排隊求中日韓德甚至馬其頓語版本的群眾們時說,他正在用維基百科規模最大的60種語言訓練模型,漢語、韓語、日語、德語、西班牙語等等都包含在其中。
就是這裡列出的1-60號語言:
https://meta.wikimedia.org/wiki/ ... _number_of_articles
另外,他們對中文做了一點比較特殊的處理,就是把CJK Unicode字符集里的所有字元token化。
項目庫中發布了哪些內容?
用於BERT模型架構的TensorFlow代碼(主要是標準的Transformer架構)。
BERT-Base和BERT-Large模型小寫和Cased版本的預訓練檢查點。
論文里微調試驗的TensorFlow代碼,比如SQuAD,MultiNLI和MRPC。 此項目庫中的所有代碼都可以直接用在CPU,GPU和雲TPU上。預訓練模型
這裡發布的是論文中的BERT-Base和BERT-Large模型。
其中,Uncased的意思是,文本在經過WordPiece token化之前,全部會調整成小寫,比如「John Smith」會變成「john smith」。Uncased模型也會剔除任何的重音標記。Cased意味著,文本的真實情況和重音標記都會保留下來。
通常情況下,Uncased模型更好,除非文本的原始信息會對你的任務來說非常重要。比如說,識別命名實體或對部分語音標記。
這些模型與源代碼(Apache 2.0)的授權相同。
在下面的模型介紹中,沿襲論文中的簡稱:層數(即 Transformer 塊)表示為L,將隱藏尺寸表示為H,將自注意力頭(self-attention heads)的數量表示為A。
複製下方鏈接到瀏覽器中即可下載
BERT-Base, Uncased:L=12,H=768,A=12,總參數=110M
https://storage.googleapis.com/b ... L-12_H-768_A-12.zip
BERT-Large, Uncased:L=24, H=1024, A=16, 總參數=340M
https://storage.googleapis.com/b ... -24_H-1024_A-16.zip
BERT-Base, Cased:L=12,H=768,A=12,總參數=110M
https://storage.googleapis.com/b ... L-12_H-768_A-12.zip
BERT-Large, Cased:L=24, H=1024, A=16, 總參數=340M
https://storage.googleapis.com/b ... L-12_H-768_A-12.zip
每個.zip文件,都包含3個東西:
一個 TensorFlow檢查點(bert_model.ckpt),一個vocab文件(vocab.txt)和一個配置文件(bert_config.json)。
如果你想對這些預訓練模型進行端到端的微調,參見這份具體操作:
https://github.com/google-resear ... ne-tuning-with-bert
使用 BERT 提取固定特徵向量(如 ELMo)
有時候,與對整個預訓練模型進行端到端的微調相比,直接獲得預訓練模型的語境嵌入會更好一些。
預訓練模型的語境嵌入,是由預訓練模型的隱藏層生成的每個token的固定語境表示。這應該能夠減輕大部分內存不足的問題。
比如,腳本extract_features.py,可以這樣使用:
# Sentence A and Sentence B are separated by the ||| delimiter.
# For single sentence inputs, don't use the delimiter.
echo'Who was Jim Henson ? ||| Jim Henson was a puppeteer'> /tmp/input.txt
python extract_features.py
--input_file=/tmp/input.txt
--output_file=/tmp/output.jsonl
--vocab_file=$BERT_BASE_DIR/vocab.txt
--bert_config_file=$BERT_BASE_DIR/bert_config.json
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt
--layers=-1,-2,-3,-4
--max_seq_length=128
--batch_size=8
這將創建一個 JSON 文件(每行輸入一行),包含由layers指定的每個Transformer層的BERT 激活(-1是Transformer的最後隱藏層,等等)
請注意,這個腳本將產生非常大的輸出文件,默認情況下,每個輸入token產生大約15kb輸出。
如果你預測訓練標籤,需要保持原始辭彙和token詞之間的一致性。具體請參閱下面的Token化部分。
Token化
對於句子層級的任務,token化非常簡單。按照run_classifier.py和extract_features.py中的代碼運行就行了。句子層級任務的基本流程是:
實例化。tokenizer = tokenization.FullTokenizer
將原始文本token化。tokens = tokenizer.tokenize(raw_text).
截斷句子長度。(最大序列你最多可以使用512,但因為內存和速度的原因,短一點可能會更好)
在正確的位置添加[ CLS ]和[ SEP ]token。
[ CLS ]是分類輸出的特殊符號,[ SEP ]是分離非連續token序列的特殊符號。
單詞級別和跨度級別的任務(例如SQuAD 和 NER)更為複雜,因為你需要保證輸入文本和輸出文本之間對齊,以便你能夠映射訓練標籤。
SQuAD是一個非常複雜的例子,因為輸入的標籤是基於字元的,而且段落的長度也經常會超過默認的最大序列。查看run_squad.py中的代碼, 可以看到Google是如何處理這個問題的。
在介紹處理單詞級別任務的通用方法之前,了解分詞器(tokenizers)到底在做什麼非常重要。它主要有三個步驟:
文本標準化:將所有的空白字元轉換為空格,在Uncased模型中,要將所有字母小寫,並剔除重音標記。例如:John Johanson』s, → john johanson』s,
標點符號分離:把標點符號分為兩個部分,也就是說,在所有的標點符號字元周圍添加空格。標點符號的定義是: (a)任何具有 p * Unicode 類的東西,(b)任何非字母 / 數字 / 空格 ASCII 字元,例如 $這樣的字元,技術上不是標點符號。例如:john johanson』s, → john johanson 『 s ,
WordPiece token化:將空白token化,應用到上述過程的輸出中,並對每個token分別應用WordPiece。(這個實現直接基於 tensor2tensor)。例如:john johanson 『 s , → john johan ##son 『 s ,
這個方案的優點在於,它與大多數英語分詞器兼容。例如,假設你有一個類似這樣的標記部分語音任務:
Input: John Johanson 『s house
Labels: NNP NNP POS NN
所有的token化輸出都是這樣的:
Tokens: john johan ##son 『 s house
至關重要的是,這與輸入John Johanson』s house的輸出是一樣的,在』之前也沒有空格。
如果你有一個帶有單詞級別註釋的預token化表示,你可以獨立地對每個輸入單詞進行簡單的分析,並確保原始文本到token化文本之間是對齊的:
### Input
orig_tokens = ["John", "Johanson", "'s", "house"]
labels = ["NNP", "NNP", "POS", "NN"]
### Output
bert_tokens = []
# Token map will be an int -> int mapping between the `orig_tokens` index and
# the `bert_tokens` index.
orig_to_tok_map = []
tokenizer = tokenization.FullTokenizer(
vocab_file=vocab_file, do_lower_case=True)
bert_tokens.append("[CLS]")
fororig_token inorig_tokens:
orig_to_tok_map.append(len(bert_tokens))
bert_tokens.extend(tokenizer.tokenize(orig_token))
bert_tokens.append("[SEP]")
# bert_tokens == ["[CLS]", "john", "johan", "##son", "'", "s", "house", "[SEP]"]
# orig_to_tok_map == [1, 2, 4, 6]
現在,orig_to_tok_map能用來將labels映射到token化表示上。
有一些常見的英語訓練方案,會導致BERT的訓練方式之間出現輕微的不匹配。
例如,如果你輸入的是縮寫單詞而且又分離開了,比如do n』t,將會出現錯誤匹配。如果可能的話,你應該預先處理數據,將其轉換為原始的文本。如果不處理,這種錯誤匹配也不是什麼大問題。
預訓練BERT
如果你想自己預訓練BERT,可以看看這份資源中在任意文本語料庫上完成「masked LM」和「預測下一句」任務的代碼。
注意:這不是論文中的原始代碼,但是同樣能生成論文中所描述的預訓練數據。原始代碼是C++寫成的,更複雜。
首先是數據生成環節:輸入每句一行的純文本文件,用空行分隔文件,會得到一組TFRecord文件格式的tf.train.Example。
python create_pretraining_data.py
--input_file=./sample_text.txt
--output_file=/tmp/tf_examples.tfrecord
--vocab_file=$BERT_BASE_DIR/vocab.txt
--do_lower_case=True
--max_seq_length=128
--max_predictions_per_seq=20
--masked_lm_prob=0.15
--random_seed=12345
--dupe_factor=5
這段腳本能把整個輸入文件中的所有樣例存儲到內存,所以,如果輸入文件比較大,你要把它分割開,多次調用這個腳本。
max_predictions_per_seq是每個序列能獲得masked LM預測的最大值,應該設置到和max_seq_length乘masked_lm_prob差不多。
數據生成之後就可以運行預訓練了。
python run_pretraining.py
--input_file=/tmp/tf_examples.tfrecord
--output_dir=/tmp/pretraining_output
--do_train=True
--do_eval=True
--bert_config_file=$BERT_BASE_DIR/bert_config.json
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt
--train_batch_size=32
--max_seq_length=128
--max_predictions_per_seq=20
--num_train_steps=20
--num_warmup_steps=10
--learning_rate=2e-5
注意,如果你要從頭開始預訓練的話,就去掉代碼里的init_checkpoint。模型的設置在bert_config_file里。
|
|





 狗仔卡
狗仔卡




 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 搶沙發
搶沙發 樓主
樓主