在五年的時間中,我們看到:新的模擬計算機(神經形態)的進步,納米線對數字計算的部分挑戰,硅光子代替了 SerDes(112GBs 以上),以及更高速的存儲器對 AI 性能提升的助益。
未來十年,AI 晶元將不僅是半導體領域最有前途的增長領域之一,還可能擾亂傳統的計算機市場。
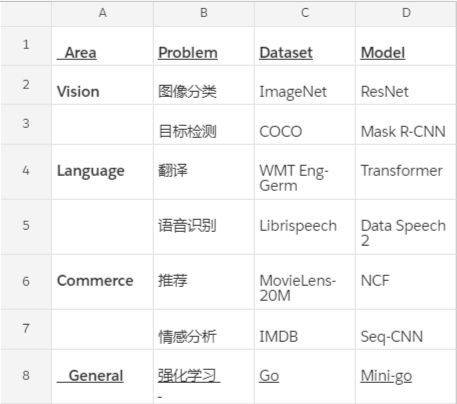
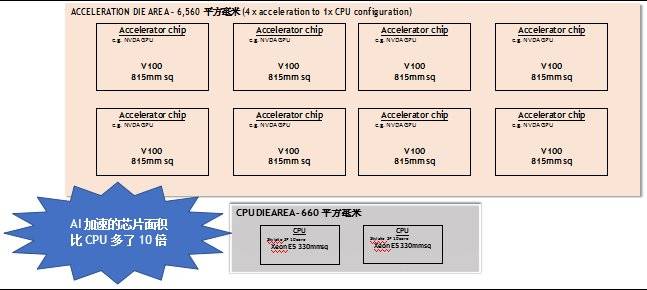
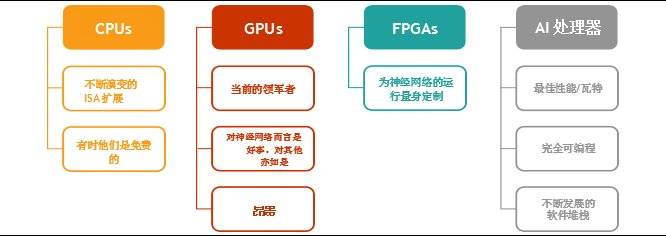
專門針對 AI 開發的軟體還有 99%沒寫出來。如今,只有不足1% 的雲伺服器為AI加速服務(今年的伺服器總數為 5 百萬台),企業伺服器則是幾乎零舉動。訓練和推理的工作量正以較低的基數倍增,但市場似乎一致認為,今天的加速硬體(GPUs,CPUs, FPGAs)已經遠遠滿足不了市場的需求——在我們看來,我們需要實現吞吐量的巨大飛躍(100 倍),以擴大 AI 的規模,並讓 AI 變得無處不在。





 狗仔卡
狗仔卡





 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 搶沙發
搶沙發 樓主
樓主