|
回復: 1
|



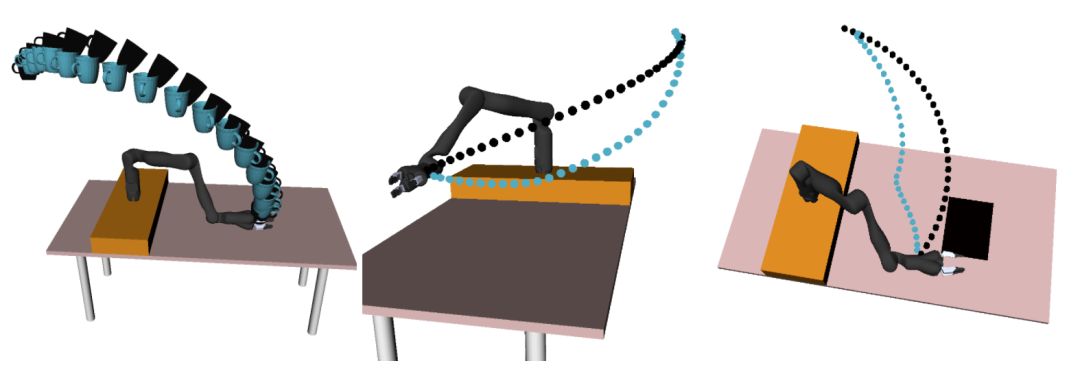
前沿 | BAIR開發現實環境的RL機器人,通過與人類的物理交互學習真實目標[複製鏈接] |
| ||
|
時代小人物. 但也有自己的思想,情感. 和道德.
|
||

 狗仔卡
狗仔卡







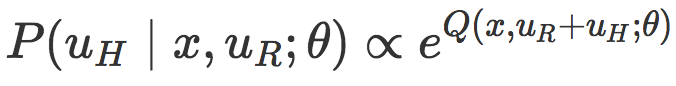
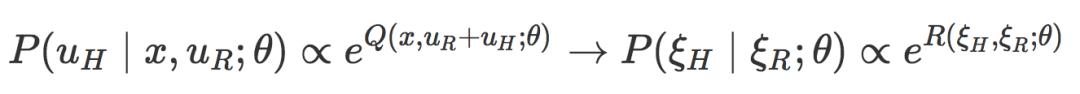



 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 搶沙發
搶沙發
| ||
|
時代小人物. 但也有自己的思想,情感. 和道德.
|
||
|
回復: 1
|
前沿 | BAIR開發現實環境的RL機器人,通過與人類的物理交互學習真實目標[複製鏈接] |
| ||
|
時代小人物. 但也有自己的思想,情感. 和道德.
|
||
| ||
|
時代小人物. 但也有自己的思想,情感. 和道德.
|
||
 樓主
樓主