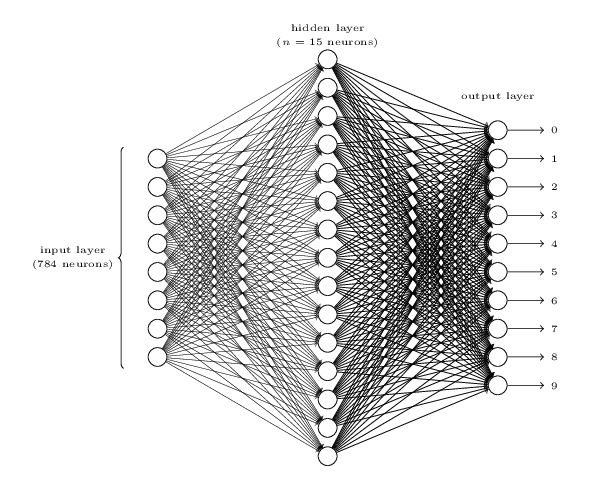
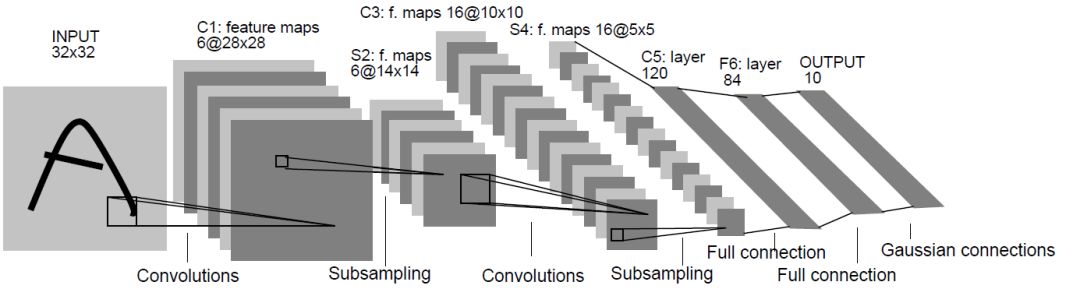
2006年,Hinton利用預訓練方法緩解了局部最優解問題,將隱含層推動到了7層(參考論文:Hinton G E, Salakhutdinov R R. Reducing the Dimensionality of Data with Neural Networks[J]. Science, 2006, 313(5786):504-507.),神經網路真正意義上有了「深度」,由此揭開了深度學習的熱潮。這裡的「深度」並沒有固定的定義——在語音識別中4層網路就能夠被認為是「較深的」,而在圖像識別中20層以上的網路屢見不鮮。為了克服梯度消失,ReLU、maxout等傳輸函數代替了 sigmoid,形成了如今 DNN的基本形式。單從結構上來說,全連接的DNN和上圖的多層感知機是沒有任何區別的。值得一提的是,今年出現的高速公路網路(highway network)和深度殘差學習(deep residual learning)進一步避免了梯度彌散問題,網路層數達到了前所未有的一百多層(深度殘差學習:152層,具體去看何愷明大神的paper)!





 狗仔卡
狗仔卡




 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 搶沙發
搶沙發