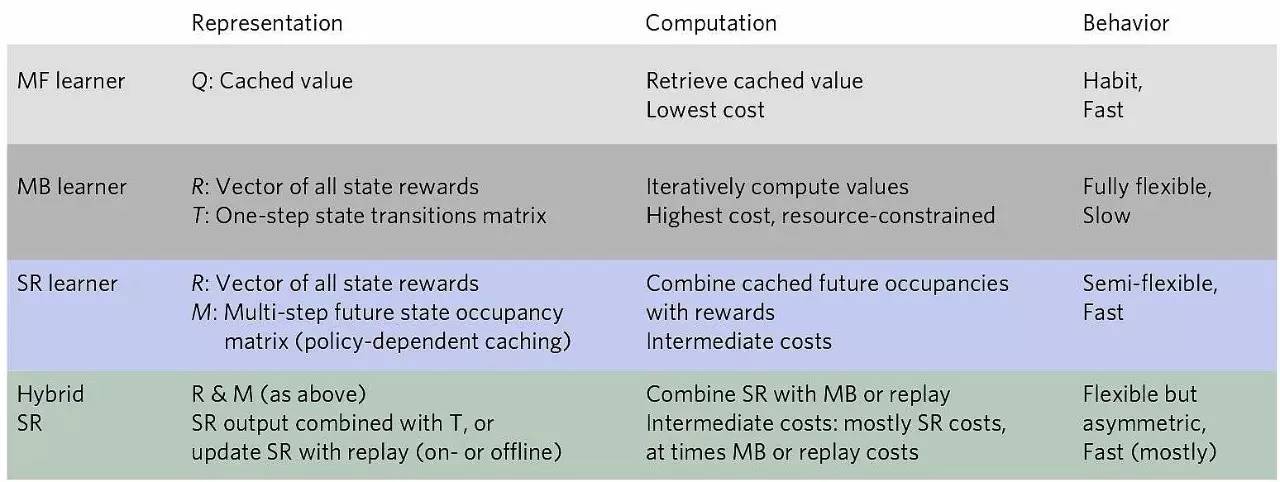
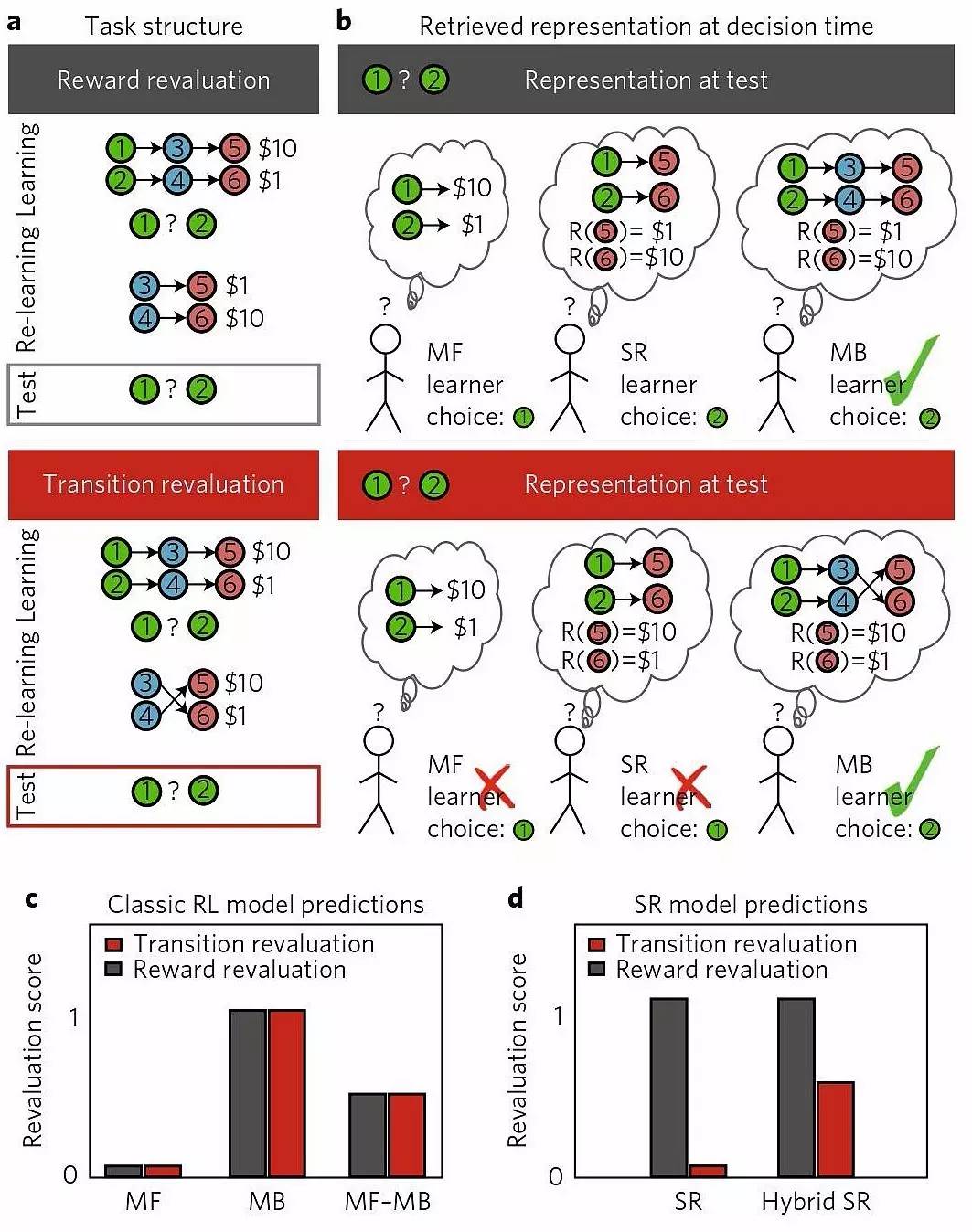
【新智元導讀】DeepMind與來自普林斯頓、NYU、達特茅斯學院、UCL和哈佛大學的研究人員合作,探索了人類行為中的強化學習,為開發智能體強化學習提供了新的策略。研究人員具體探討了一種存在於無模型和基於模型的學習演演算法之間的方法,基於後繼表示(successor representation,SR),將長期狀態預測存入緩存中。作者預計,這些發現將為計算科學、電生理學和神經影像學研究開闢新的途徑去研究評估機制的神經基礎。相關論文《The successor representation in human reinforcement learning》日前在Nature子刊《自然-人類行為》上發表。
為此,普林斯頓、NYU、達特茅斯學院、DeepMind兼UCL以及哈佛大學的研究人員,設計了兩項實驗,探索了大腦決策時是否使用了存在於MF和MB之間的演演算法,以及這種演演算法與MF、MB之間的異同。相關論文《The successor representation in human reinforcement learning》日前在Nature子刊《自然-人類行為》上發表。





 狗仔卡
狗仔卡




 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 搶沙發
搶沙發