|
|
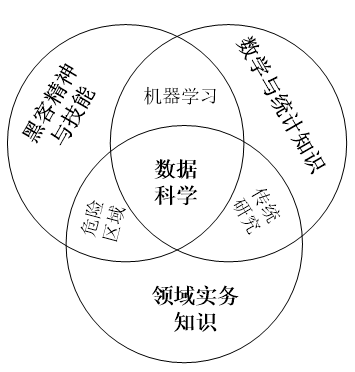
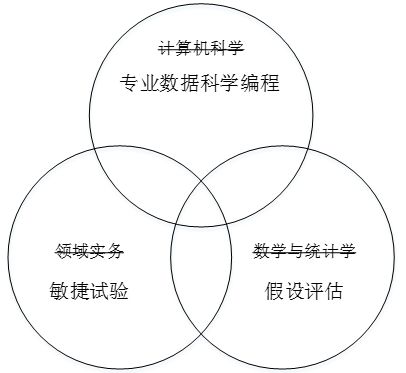
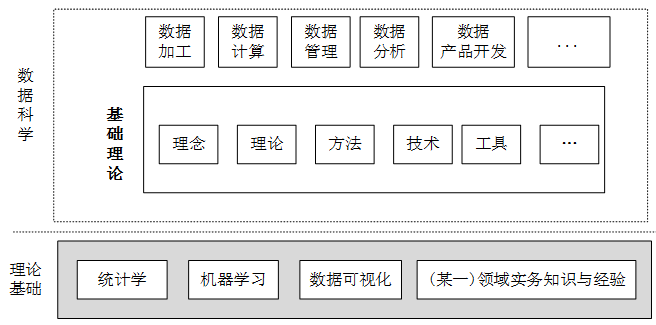
(8)準確定位人才培養目的。數據科學的學習和人才培養的目的是培養數據科學家而不是數據工程師。二者的區別在於,數據工程師負責的是「數據本身的管理」,而數據科學家的主要職責是「基於數據的管理」,包括基於數據的分析、決策、流程定義與再造、產品設計和服務提供等。因此,相對於數據工程師,數據科學家對人才的要求更高,不僅要有理論功底和實踐經驗,而且還要求有精神素質,即創造性設計、批判性思考和好奇性提問的能力。
參考文獻
[1]John Walker S. Big data: A revolution that will transform how we live, work, and think[J]. 2014.
[2]Boyd D, Crawford K. Critical questions for big data: Provocations for a cultural, technological, and scholarly phenomenon[J]. Information, communication & society, 2012, 15(5): 662-679.
[3]Kitchin R. Big Data, new epistemologies and paradigm shifts[J]. Big Data & Society, 2014, 1(1): 2053951714528481.
[4]Jagadish H V. Big data and science: myths and reality[J]. Big Data Research, 2015, 2(2): 49-52.
[5]Provost F, Fawcett T. Data science and its relationship to big data and data-driven decision making[J]. Big Data, 2013, 1(1): 51-59.
[6]Naur P. Concise survey of computer methods[M]Studentlitteratur AB: 1974.
[7]Cleveland W S. Data science: an action plan for expanding the technical areas of the field of statistics[J]. International statistical review, 2001, 69(1): 21-26.
[8]Mattmann C A. Computing: A vision for data science[J]. Nature, 2013, 493(7433): 473-475.
[9]Dhar V. Data science and prediction[J]. Communications of the ACM, 2013, 56(12): 64-73.
[10]Patil T, Davenport T. Data scientist: the sexiest job of the 21st century[J]. Harvard Business Review, 2012.
[11]Kitchin R. Big data and human geography: Opportunities, challenges and risks[J]. Dialogues in human geography, 2013, 3(3): 262-267.
[12]Smith M. The White House names Dr. DJ Patil as the first US chief data scientist[J]. The White House Blog, 2015.
[13]Gartner J. Gartner』s 2014 hype cycle for emerging technologies maps the journey to digital business[OL]. http://www.gartner.com/newsroom/id/2819918.
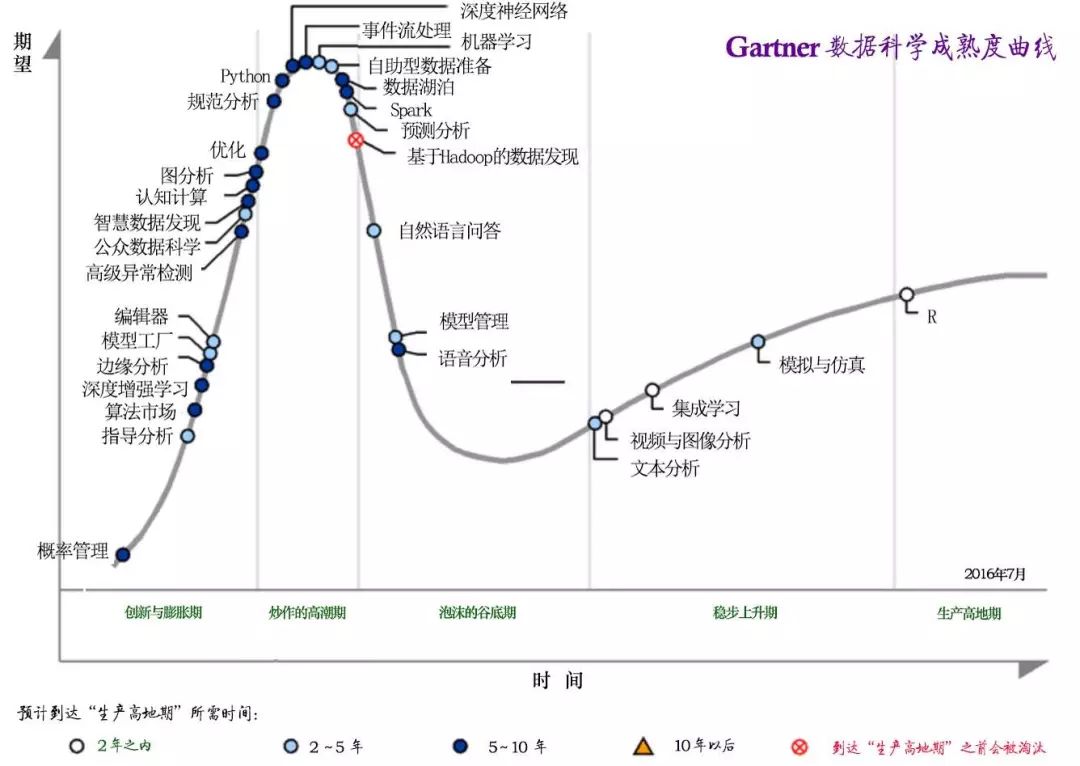
[14]Gartner J. Hype Cycle for Data Science, 2016 [OL]. https://www.gartner.com/doc/3388917/hype-cycle-data-science-.(25 July 2016 )
[15]Schutt R, O'Neil C. Doing data science: Straight talk from the frontline[M]. O'Reilly Media, Inc., 2013:7.
[16]Jerry Overton.Going Pro in Data Science [M].O』Reilly Media, Inc,2016:12.
[17]朝樂門.數據科學理論與實踐[M].北京:清華大學出版社,2017:15.
[18]Gray J, Chambers L, Bounegru L. The data journalism handbook: how journalists can use data to improve the news[M]. " O'Reilly Media, Inc.", 2012.
[19]Kalidindi S R, De Graef M. Materials data science: current status and future outlook[J]. Annual Review of Materials Research, 2015, 45: 171-193.
[20]Fang B, Zhang P. Big Data in Finance[M]//Big Data Concepts, Theories, and Applications. Springer International Publishing, 2016: 391-412.
[21]Davis K. Ethics of Big Data: Balancing risk and innovation[M]. " O'Reilly Media, Inc.", 2012.
[22]West D M. Big data for education: Data mining, data analytics, and web dashboards[J]. Governance Studies at Brookings, 2012, 4: 1-0.
[23]Labrinidis A, Jagadish H V. Challenges and opportunities with big data[J]. Proceedings of the VLDB Endowment, 2012, 5(12): 2032-2033.
[24]Kaisler S, Armour F, Espinosa J A, et al. Big data: Issues and challenges moving forward[C].System Sciences (HICSS), 2013 46th Hawaii International Conference on. IEEE, 2013: 995-1004.
[25]Chen H, Chiang R H L, Storey V C. Business intelligence and analytics: From big data to big impact[J]. MIS quarterly, 2012, 36(4).
[26]Provost F, Fawcett T. Data science and its relationship to big data and data-driven decision making[J]. Big Data, 2013, 1(1): 51-59.
[27]Cleveland W S. Data science: an action plan for expanding the technical areas of the field of statistics[J]. International statistical review, 2001, 69(1): 21-26.
[28]Mattmann C A. Computing: A vision for data science[J]. Nature, 2013, 493(7433): 473-475.
[29]Schutt R, O'Neil C. Doing data science: Straight talk from the frontline[M]. " O'Reilly Media, Inc.", 2013.
[30]Shanahan J G, Dai L. Large scale distributed data science using apache spark[C]//Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2015: 2323-2324.
[31]Holmes A. Hadoop in practice[M]. Manning Publications Co., 2012.
[32]Sharma S, Shandilya R, Patnaik S, et al. Leading NoSQL models for handling Big Data: a brief review[J]. International Journal of Business Information Systems, 2016, 22(1): 1-25.
[33]Sadalage P J, Fowler M. NoSQL distilled: a brief guide to the emerging world of polyglot persistence[M]. Pearson Education, 2012.
[34]Marx V. Biology: The big challenges of big data[J]. Nature, 2013, 498(7453): 255-260.
[35]Raghupathi W, Raghupathi V. Big data analytics in healthcare: promise and potential[J]. Health information science and systems, 2014, 2(1): 3.
[36]Kim G H, Trimi S, Chung J H. Big-data applications in the government sector[J]. Communications of the ACM, 2014, 57(3): 78-85.
[37]Daniel B. Big data and analytics in higher education: Opportunities and challenges[J]. British journal of educational technology, 2015, 46(5): 904-920.
[38]George G, Haas M R, Pentland A. Big data and management[J]. Academy of Management Journal, 2014, 57(2): 321-326.
[39]Swan M. The quantified self: Fundamental disruption in big data science and biological discovery[J]. Big Data, 2013, 1(2): 85-99.
[40]Lewis S C. Journalism in an Era of Big Data: Cases, concepts, and critiques[J]. 2015.
[41]Rahm E. Big Data Analytics[J]. it-Information Technology, 2016, 58(4): 155-156.
[42]Baumer B. A data science course for undergraduates: Thinking with data[J]. The American Statistician, 2015, 69(4): 334-342.
[43]Hardin J, Hoerl R, Horton N J, et al. Data science in statistics curricula: Preparing students to 「think with data」[J]. The American Statistician, 2015, 69(4): 343-353.
[44]Cassel L N, Posner M, Dicheva D, et al. Advancing data science for students of all majors[C]//Proceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science Education. ACM, 2017: 722-722.
[45]Berman F D, Bourne P E. Let's make gender diversity in data science a priority right from the start[J]. PLoS biology, 2015, 13(7): e1002206.
[46]Lemen Chao.Data Science [M].Tsinghua University Press,2016.
[47]Cooper P. Data, information, knowledge and wisdom[J]. Anaesthesia & Intensive Care Medicine, 2014, 15(1): 44-45.
[48]Erl T, Khattak W, Buhler P. Big data fundamentals: concepts, drivers & techniques[M]. Prentice Hall Press, 2016.
[49]Wang G, Gunasekaran A, Ngai E W T, et al. Big data analytics in logistics and supply chain management: Certain investigations for research and applications[J]. International Journal of Production Economics, 2016, 176: 98-110.
[50]Cardenas A A, Manadhata P K, Rajan S P. Big data analytics for security[J]. IEEE Security & Privacy, 2013, 11(6): 74-76.
[51]Raghupathi W, Raghupathi V. Big data analytics in healthcare: promise and potential[J]. Health information science and systems, 2014, 2(1): 3.
[52]Jeffery T. Leek, Roger D. Peng.What is the question? Mistaking the type of question being considered is the most common error in data analysis[J].Science,2015,374(6228):1314-1315.
[53]Swan M. The quantified self: Fundamental disruption in big data science and biological discovery[J]. Big Data, 2013, 1(2): 85-99.
[54]Ruckenstein M, Pantzar M. Beyond the quantified self: Thematic exploration of a dataistic paradigm[J]. new media & society, 2017, 19(3): 401-418.
[55]Khatri V, Brown C V. Designing data governance[J]. Communications of the ACM, 2010, 53(1): 148-152.
[56]Khatri V, Brown C V. Designing data governance[J]. Communications of the ACM, 2010, 53(1): 148-152.
[57]Thomas G. The DGI data governance framework[J]. The Data Governance Institute, Orlando, FL (USA), 2006.
[58]Lee S U, Zhu L, Jeffery R. Design Choices for Data Governance in Platform Ecosystems: A Contingency Model[J]. arXiv preprint arXiv:1706.07560, 2017.
[59]CMMI Institute.Data Management Maturity (DMM)℠ Model[OL].http://cmmiinstitute.com/data-management-maturity
[60]Liu J, Li J, Li W, et al. Rethinking big data: A review on the data quality and usage issues[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 115: 134-142.
[61]李建中, 王宏志, 高宏. 大數據可用性的研究進展[J]. 軟體學報, 2016, 27(7): 1605-1625.
[62]Rahm E, Do H H. Data cleaning: Problems and current approaches[J]. IEEE Data Eng. Bull., 2000, 23(4): 3-13.
[63]Wickham H. Tidy data[J]. Journal of Statistical Software, 2014, 59(10): 1-23.
[64]Lafuente G. The big data security challenge[J]. Network security, 2015, 2015(1): 12-14.
[65]Perera C, Ranjan R, Wang L, et al. Big data privacy in the internet of things era[J]. IT Professional, 2015, 17(3): 32-39.
[66]Patil D, Noren A. Building Data Science Teams: The Skills, Tools and Perspectives Behind Great Data Science Groups[M]. O'Reilly, 2011.
[67]Banerjee S. Citizen Data Science for Social Good: Case Studies and Vignettes from Recent Projects. doi: 10.13140/RG. 2.1. 1846.6002[J]. URL https://www. researchgate. net/publication/283119007_Citizen_Data_Science_for_Social_Goo d_Case_Studies_and_Vignettes_from_Recent_Projects, 2015.
[68]Parasie S, Dagiral E. Data-driven journalism and the public good:「Computer-assisted-reporters」 and 「programmer-journalists」 in Chicago[J]. New media & society, 2013, 15(6): 853-871.
[69]Du D, Li A, Zhang L. Survey on the applications of big data in Chinese real estate enterprise[J]. Procedia Computer Science, 2014, 30: 24-33.
[70]Middleton S E, Shadbolt N R, De Roure D C. Ontological user profiling in recommender systems[J]. ACM Transactions on Information Systems (TOIS), 2004, 22(1): 54-88.
[71]Marshall P, Todd B, Rhodes M. Ultimate Guide to Google AdWords[M]. Entrepreneur Press, 2014.
[72]Gurrin C, Smeaton A F, Doherty A R. Lifelogging: Personal big data[J]. Foundations and Trends® in Information Retrieval, 2014, 8(1): 1-125.
[73]Raghupathi W, Raghupathi V. Big data analytics in healthcare: promise and potential[J]. Health information science and systems, 2014, 2(1): 3.
[74]Marx V. Biology: The big challenges of big data[J]. Nature, 2013, 498(7453): 255-260.
[75]Bello-Orgaz G, Jung J J, Camacho D. Social big data: Recent achievements and new challenges[J]. Information Fusion, 2016, 28: 45-59.
[76]Mohanty S, Jagadeesh M, Srivatsa H. Big data imperatives: Enterprise 『Big Data』warehouse,『BI』implementations and analytics[M]. Apress, 2013.
[77]Bertot J C, Gorham U, Jaeger P T, et al. Big data, open government and e-government: Issues, policies and recommendations[J]. Information Polity, 2014, 19(1, 2): 5-16.
[78]Aggarwal A. Opportunities and Challenges of Big Data in Public Sector[J]. Managing Big Data Integration in the Public Sector, 2015: 289.
[79]Matt Turck.Big Data Landscape 2016 v18 FINAL[OL].(2016-4-28).http://mattturck.com/big-data-landscape-2016-v18-final/
[80]Kaisler S, Armour F, Espinosa J A, et al. Big data: Issues and challenges moving forward[C]//System Sciences (HICSS), 2013 46th Hawaii International Conference on. IEEE, 2013: 995-1004
[81]Al-Jarrah, Omar Y., et al. "Efficient machine learning for big data: A review." Big Data Research 2.3 (2015): 87-93.
[82]Batra, Surinder. "Big data analytics and its reflections on DIKW hierarchy." Review of Management 4.1/2 (2014): 5.
[83]Donhost M J, Anfara Jr V A. Data-driven decision making[J]. Middle School Journal, 2010, 42(2): 56-63.
[84]Chen C L P, Zhang C Y. Data-intensive applications, challenges, techniques and technologies: A survey on Big Data[J]. Information Sciences, 2014, 275: 314-347.
[85]Voulgaris Z, Magoulas G D. Extensions of the k nearest neighbour methods for classification problems[C]//Proc. of the 26th IASTED International Conference on Artificial Intelligence and Applications (AIA), Innsbruck, Austria, February 11. 2008, 13: 23-28.
[86]Datawocky.More data usually beats better algorithms[OL].(2008-3-24).http://anand.typepad.com/datawocky/2008/03/more-data-usual.html
[87]Kleppmann, Martin. Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems. " O'Reilly Media, Inc.", 2017.
[88]Eric Brewer.Parallelism in the Cloud[OL].(2013-6-24)
.https://www.usenix.org/sites/def ... hotpar13_slides.pdf
[89]McAfee A, Brynjolfsson E, Davenport T H. Big data: the management revolution[J]. Harvard business review, 2012, 90(10): 60-68.
[90]Fan, Jianqing, Fang Han, and Han Liu. "Challenges of big data analysis." National science review 1.2 (2014): 293-314.
[91]Edgar, Robert C. "MUSCLE: a multiple sequence alignment method with reduced time and space complexity." BMC bioinformatics 5.1 (2004): 113.
[92]Ginsberg J, Mohebbi M H, Patel R S, et al. Detecting influenza epidemics using search engine query data[J]. Nature, 2009, 457(7232): 1012-1014.
[93]Lazer D, Kennedy R, King G, et al. The Parable of Google Flu: Traps in Big Data Analysis[J]. Science, 2014, 343(6176): 1203-1205.
[94]Tansley, Stewart, and Kristin M. Tolle. The fourth paradigm: data-intensive scientific discovery. Ed. Tony Hey. Vol. 1. Redmond, WA: Microsoft research, 2009.
[95]Provost F, Fawcett T. Data science and its relationship to big data and data-driven decision making[J]. Big Data, 2013, 1(1): 51-59.
[96]Dhar V, Chou D. A comparison of nonlinear models for financial prediction[J]. IEEE Transactions on Neural networks, 2001, 12(4): 907-921.
[97]Føllesdal, Dagfinn. "Hermeneutics and the hypothetico‐deductive method." Dialectica 33.3‐4 (1979): 319-336.
[98]Blumer A, Ehrenfeucht A, Haussler D, et al. Occam's razor[J]. Information processing letters, 1987, 24(6): 377-380.
[99]LeCun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[100]Liu Z H, Hammerschmidt B, McMahon D. JSON data management: supporting schema-less development in RDBMS[C]//Proceedings of the 2014 ACM SIGMOD international conference on Management of data. ACM, 2014: 1247-1258.
[101]Brewer E. CAP twelve years later: How the" rules" have changed[J]. Computer, 2012, 45(2): 23-29.
[102]Zaharia M, Chowdhury M, Franklin M J, et al. Spark: Cluster computing with working sets[J]. HotCloud, 2010, 10(10-10): 95.
[103]Plunkett, Tom, et al. Oracle Big Data Handbook. McGraw-Hill Osborne Media, 2013.
[104]Patil D J. Data Jujitsu: the art of turning data into product[M]. " O'Reilly Media, Inc.", 2012.
[105]Leadbeater C, Miller P. The Pro-Am revolution: How enthusiasts are changing our society and economy[M]. Demos, 2004.
[106]Conway D. Data Science in the US Intelligence Community[J]. IQT Quarterly, 2011, 2(4): 24-27.
[107]Anderson P, McGuffee J, Uminsky D. Data science as an undergraduate degree[C]//Proceedings of the 45th ACM technical symposium on Computer science education. ACM, 2014: 705-706.
[108]Marshall L, Eloff J H P. Towards an Interdisciplinary Master』s Degree Programme in Big Data and Data Science: A South African Perspective[C]//Annual Conference of the Southern African Computer Lecturers' Association. Springer International Publishing, 2016: 131-139.
[109]West J D, Portenoy J. 10 The Data Gold Rush in Higher Education[J]. Big Data Is Not a Monolith, 2016: 129.
[110]Anderson P, Bowring J, McCauley R, et al. An undergraduate degree in data science: curriculum and a decade of implementation experience[C]//Proceedings of the 45th ACM technical symposium on Computer science education. ACM, 2014: 145-150.
[111]Muensterer O J, Lacher M, Zoeller C, et al. Google Glass in pediatric surgery: an exploratory study [J]. International journal of surgery, 2014, 12(4): 281-289.
備註
基金項目:國家自然科學基金項目(91646202;71103020);國家社會科學基金(15BTQ054;12&ZD220)
作者簡介:朝樂門(1979-),男,中國人民大學副教授,博士生導師,研究方向:數據科學與大數據分析;邢春曉(1967-),男,清華大學教授,博士生導師,研究方向:雲計算與大數據分析;張勇(1973-),男,清華大學副教授,博士生導師,研究方向:數據管理與大數據分析。 |
|





 狗仔卡
狗仔卡




 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 搶沙發
搶沙發 樓主
樓主