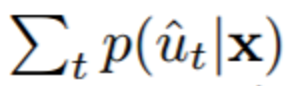|
|
如何通過機器學習解讀唇語?DeepMind要通過LipNet幫助機器「看」懂別人說的話
機器之心mp2016-11-06 16:45:07閱讀(356)評論(0)
選自oxml.co.uk
機器之心編譯
參與:吳攀
還記得經典科幻電影《2001 太空漫遊》中的飛船主控計算機 Hall 嗎?它具有依靠閱讀說話人的嘴唇運動理解其所表達的內容的能力,這種能力也在推動那個幻想故事的情節發展中起到了至關重要的作用。近日,牛津大學、Google DeepMind 和加拿大高等研究院(CIFAR)聯合發布了一篇同樣具有重要價值的論文,介紹了利用機器學習實現的句子層面的自動唇讀技術 LipNet。該技術將自動唇讀技術的前沿水平推進到了前所未有的高度。原論文可點擊文末「閱讀原文」下載。

摘要
唇讀(lipreading)是指根據說話人的嘴唇運動解碼出文本的任務。傳統的方法是將該問題分成兩步解決:設計或學習視覺特徵、以及預測。最近的深度唇讀方法是可以端到端訓練的(Wand et al., 2016; Chung & Zisserman, 2016a)。但是,所有已經存在的方法都只能執行單個詞的分類,而不是句子層面的序列預測。研究已經表明,人類在更長的話語上的唇讀表現會更好(Easton & Basala, 1982),這說明了在不明確的通信通道中獲取時間背景的特徵的重要性。受到這一觀察的激勵,我們提出了 LipNet——一種可以將可變長度的視頻序列映射成文本的模型,其使用了時空卷積、一個 LSTM 循環網路和聯結主義的時間分類損失(connectionist temporal classification loss),該模型完全是以端到端的形式訓練的。我們充分利用我們的知識,LipNet 是第一個句子層面的唇讀模型,其使用了一個單端到端的獨立於說話人的深度模型來同時地學習時空視覺特徵(spatiotemporal visual features)和一個序列模型。在 GRID 語料庫上,LipNet 實現了 93.4% 的準確度,超過了經驗豐富的人類唇讀者和之前的 79.6% 的最佳準確度。
1 引言
唇讀在人類的交流和語音理解中發揮了很關鍵的作用,這被稱為「麥格克效應(McGurk effect)」(McGurk & MacDonald, 1976),說的是當一個音素在一個人的說話視頻中的配音是某個人說的另一個不同的音素時,聽話人會感知到第三個不同的音素。
唇讀對人類來說是一項眾所周知的艱難任務。除了嘴唇和有時候的舌頭和牙齒,大多數唇讀信號都是隱晦的,難以在沒有語境的情況下分辨(Fisher, 1968; Woodward & Barber, 1960)。比如說,Fisher (1968) 為 23 個初始輔音音素的列表給出了 5 類視覺音素(visual phoneme,被稱為 viseme),它們常常會在人們觀察說話人的嘴唇時被混淆在一起。許多這些混淆都是非對稱的,人們所觀察到的最終輔音音素是相似的。
所以說,人類的唇讀表現是很差的。聽覺受損的人在有 30 個單音節詞的有限子集上的準確度僅有 17±12%,在 30 個複合詞上也只有 21±11%(Easton & Basala, 1982)。
因此,實現唇讀的自動化是一個很重要的目標。機器讀唇器(machine lipreaders)有很大的實用潛力,比如可以應用於改進助聽器、公共空間的靜音聽寫、秘密對話、嘈雜環境中的語音識別、生物特徵識別和默片電影處理。機器唇讀是很困難的,因為需要從視頻中提取時空特徵(因為位置(position)和運動(motion)都很重要)。最近的深度學習方法試圖通過端到端的方式提取這些特徵。但是,所有的已有工作都只是執行單個詞的分類,而非句子層面的序列預測(sentence-level sequence prediction)。
在這篇論文中,我們提出了 LipNet。就我們所知,這是第一個句子層面的唇讀模型。就像現代的基於深度學習的自動語音識別(ASR)一樣,LipNet 是以端到端的方式訓練的,從而可以做出獨立於說話人的句子層面的預測。我們的模型在字元層面上運行,使用了時空卷積神經網路(STCNN)、LSTM 和聯結主義時間分類損失(CTC)。
我們在僅有的一個公開的句子層面的數據集 GRID 語料庫(Cooke et al., 2006)上的實驗結果表明 LipNet 能達到 93.4% 的句子層面的詞準確度。與此對應的,之前在這個任務上的獨立於說話人的詞分類版本的最佳結果是 79.6%(Wand et al., 2016)。
我們還將 LipNet 的表現和聽覺受損的會讀唇的人的表現進行了比較。平均來看,他們可以達到 52.3% 的準確度,LipNet 在相同句子上的表現是這個成績的 1.78 倍。
最後,通過應用顯著性可視化技術(saliency visualisation techniques (Zeiler & Fergus, 2014; Simonyan et al., 2013)),我們解讀了 LipNet 的學習行為,發現該模型會關注視頻中在語音上重要的區域。此外,通過在音素層面上計算視覺音素(viseme)內和視覺音素間的混淆矩陣(confusion matrix),我們發現 LipNet 少量錯誤中的幾乎所有都發生在視覺音素中,因為語境有時候不足以用於消除歧義。
2 相關工作
本節介紹了其它在自動唇讀研究上的工作,包含了自動唇讀、使用深度學習進行分類、語音識別中的序列預測、唇讀數據集四個方面。但由於篇幅限制,機器之心未對此節進行編譯,詳情請查看原論文。
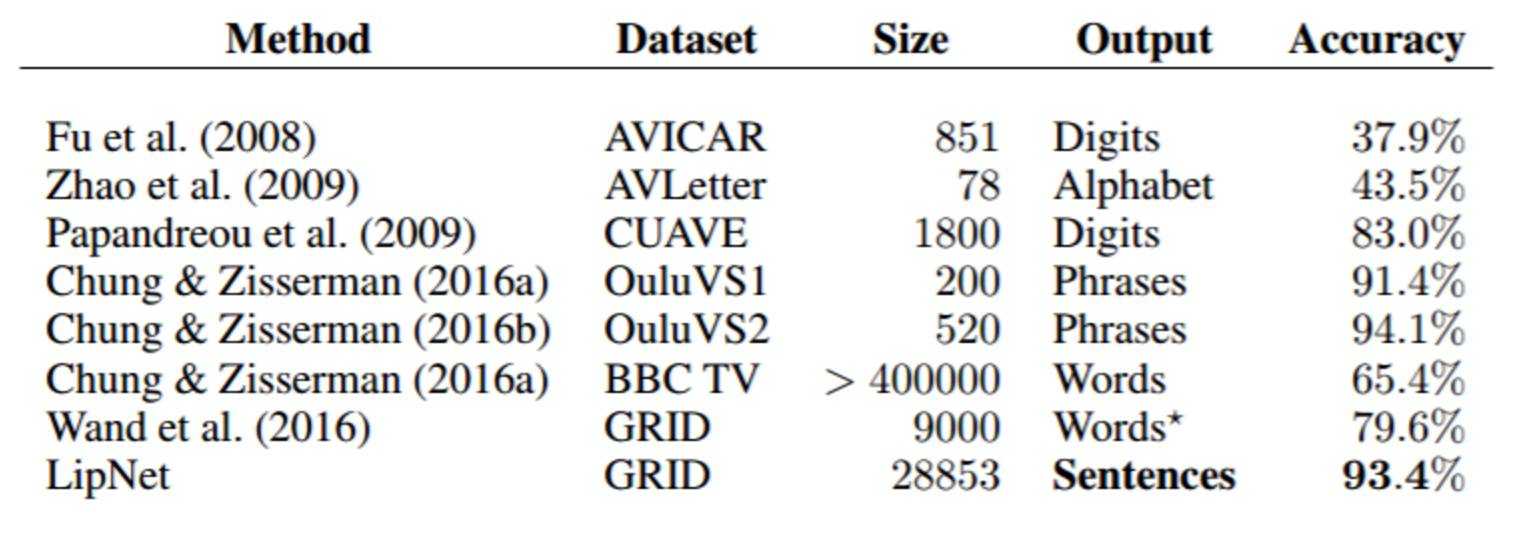
表 1:現有的唇讀數據集和對應數據集上已被報告出來的最佳準確度。Size 這一欄是指作者訓練時所用的話語的數量。儘管 GRID 語料庫包含了整個句子,但 Wand et al. (2016) 只考慮了更簡單的預測單獨的詞的情況。LipNet 預測的是句子,因此可以利用時間語境來實現更高的準確度。短語層面的方法被當作簡單的分類看待。
3 LipNet
LipNet 是一種用於唇讀的神經網路架構,其可以將不同長度的視頻幀序列映射成文本序列,而且可以通過端到端的形式訓練。在本節中,我們將描述 LipNet 的構建模塊和架構。
3.1 時空卷積
卷積神經網路(CNN)包含了可在一張圖像進行空間運算的堆疊的卷積(stacked convolutions),其可用於提升以圖像為輸入的目標識別等計算機視覺任務的表現(Krizhevsky et al., 2012)。一個從 C 通道到 C' 通道的基本 2D 卷積層(沒有偏置(bias),以單位步長)的計算:

對於輸入 x 和權重:
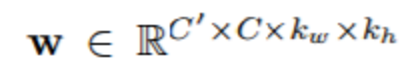
其中我們定義當 i,j 在範圍之外時,xcij=0.
時空卷積神經網路(STCNN)可以通過在時間和空間維度上進行卷積運算來處理視頻數據:
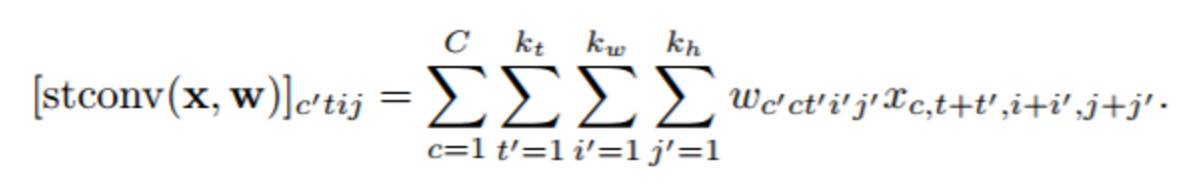
3.2 長短期記憶
長短期記憶(LSTM)(Hochreiter & Schmidhuber, 1997)是一類在早期的循環神經網路(RNN)上改進的 RNN,其加入了單元(cell)和門(gate)以在更多的時間步驟上傳播信息和學習控制這些信息流。我們使用了帶有遺忘門(forget gates)的標準 LSTM 形式:

其中 z := {z1, . . . , zT } 是 LSTM 的輸入序列,是指元素之間的乘法(element-wise multiplication), sigm(r) = 1/(1 + exp(?r))。
我們使用了 Graves & Schmidhuber (2005) 介紹的雙向 LSTM(Bi-LSTM):一個 LSTM 映射
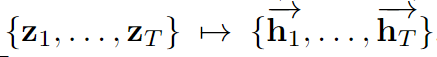
,另一個是
,然後
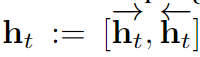
,該 Bi-LSTM 可確保 ht 在所有的 t' 上都依賴於 zt'。為了參數化一個在序列上的分佈,在時間步驟 t,讓 p(ut|z) = softmax(mlp(ht;Wmlp)),其中 mlp 是一個權重為 Wmlp 的前向網路。然後我們可以將長度 T 的序列上的分佈定義為
,其中 T 由該 LSTM 的輸入 z 確定。在 LipNet 中,z 是該 STCNN 的輸出。
3.3 聯結主義的時間分類
聯結主義的時間分類損失(onnectionist temporal classification (CTC) loss)(Graves et al., 2006)已經在現代的語音識別領域得到了廣泛的應用,因為這讓我們不再需要將訓練數據中的輸入和目標輸出對齊(Amodei et al., 2015; Graves & Jaitly, 2014; Maas et al., 2015)。給定一個在 token 類(辭彙)上輸出一個離散分佈序列的模型——該 token 類使用了一個特殊的「空白(blank)」token 進行增強,CTC 通過在所有定義為等價一個序列的序列上進行邊緣化而計算該序列的概率。這可以移除對對齊(alignment)的需求,還同時能解決可變長度的序列。用 V 表示該模型在其輸出(辭彙)的單個時間步驟上進行分類的 token 集,而空白增強過的辭彙
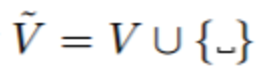
其中空格符號表示 CTC 的空白。定義函數 B : V? ? → V ?,給定 V? 上的一個字元串,刪除相鄰的重複字元並移除空白 token。對於一個標籤序列 y ∈ V ?,CTC 定義
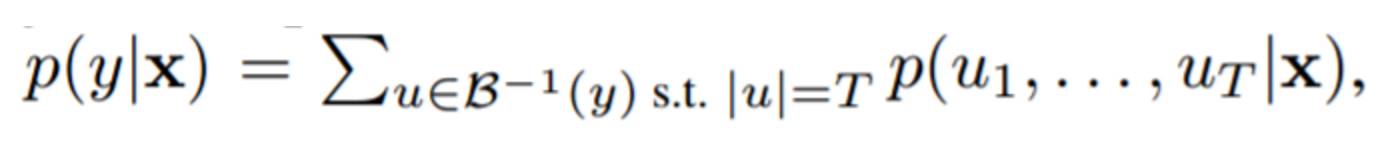
其中 T 是該序列模型中時間步驟的數量。比如,如果 T=3,CTC 定義字元串「am」的概率為
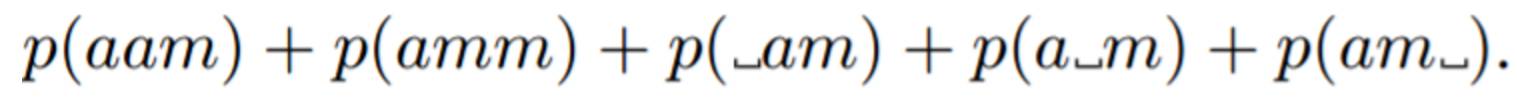
這個和可以通過動態編程(dynamic programming)有效地計算出來,讓我們可以執行最大似然(maximum likelihood)

圖 1:LipNet 架構。一個 T 幀的序列被用作輸入,被一個 3 層的 STCNN 處理,其中每一層後面都有一個空間池化層(spatial max-pooling layer)。提取出的特徵是時間上上採樣(up-sample)的,並會被一個 Bi-LSTM 處理;LSTM 輸出的每一個時間步驟會由一個 2 層前向網路和一個 softmax 處理。這個端到端的模型是用 CTC 訓練的。
3.4 LipNet 架構
圖 1 給出了 LipNet 的架構,其始於 3×(時空卷積、通道上的 dropout、空間最大池化),後面跟隨時間維度中的上採樣。
因為人類每秒鐘大約能發出 7 個音素,而且因為 LipNet 是在字元層面上工作的,所以我們總結得到:每秒輸出 25 個 token(視頻的平均幀率)對 CTC 來說太受限了。時間上採樣(temporal up-sampling)允許在字元輸出之間有更多的空格。當許多詞有完全相同的連續字元時,這個問題會加劇,因為他們之間需要一個 CTC 空白。
隨後,該時間上採樣後面跟隨一個 Bi-LSTM。該 Bi-LSTM 對 STCNN 輸出的有效進一步會聚是至關重要的。最後在每一個時間步驟上應用一個前向網路,後面跟隨一個使用了 CTC 空白和 CTC 損失在辭彙上增強了的 softmax。所有的層都是用了修正線性單元(ReLU)激活函數。超參數等更多細節可參閱附錄 A 的表 3.
|
|





 狗仔卡
狗仔卡




 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 搶沙發
搶沙發 樓主
樓主