|
|
步驟7:分析結果
識別用戶行為數據,假說成立,或根據觀察結果反駁例子:用戶滿意度評級與頁面載入時間的比重是多少。
Q13「長」數據和「寬」數據有什麼不同之處?
回答者:Gregory Piatetsky
在大多數數據挖掘/數據科學應用記錄(行)比特性(列)更多——這些數據有時被稱為「高」(或「長」)的數據。
在某些應用程序中,如基因組學和生物信息學,你可能只有一個小數量的記錄(病人),如100,或許是20000為每個病人的觀察。為了「高」工作數據的標準方法將導致過度擬合數據,所以需要特殊的方法。
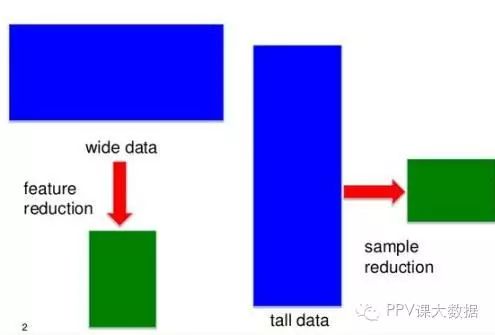
圖13.對於高數據和寬數據不同的方法,與表示稀疏篩查確切數據簡化,by Jieping Ye。
問題不僅僅是重塑數據(這裡是有用的R包),還要避免假陽性,通過減少特徵找到最相關的數據。
套索等方法減少特性和稀疏覆蓋在統計學習:套索和概括,由Hastie Tibshirani,Wainwright。(你可以免費下載PDF的書)套索等方法減少特性,在「統計學習稀疏」中很好地包含了:《套索和概括》by Hastie, Tibshirani, and Wainwright(你可以免費下載PDF的書)
Q14你用什麼方法確定一篇文章(比如報紙上的)中公布的統計數字是錯誤的或者是為了支持作者觀點,而不是關於某主題正確全面的事實信息?
一個簡單的規則,由Zack Lipton建議的:如果一些統計數據發表在報紙上,那麼它們是錯的。這裡有一個更嚴重的答案,來自 Anmol Rajpurohit:每一個媒體組織都有目標受眾。這個選擇很大地影響著決策,如這篇文章的發布、如何縮寫一篇文章,一篇文章強調的哪一部 分,如何敘述一個給定的事件等。
確定發表任何文章統計的有效性,第一個步驟是檢查出版機構和它的目標受眾。即使是相同的新聞涉及的統計數據,你會注意到它的出版非常不同,在福克斯 新聞、《華爾街日報》、ACM/IEEE期刊都不一樣。因此,數據科學家很聰明的知道在哪裡獲取消息(以及從來源來判斷事件的可信度!)。
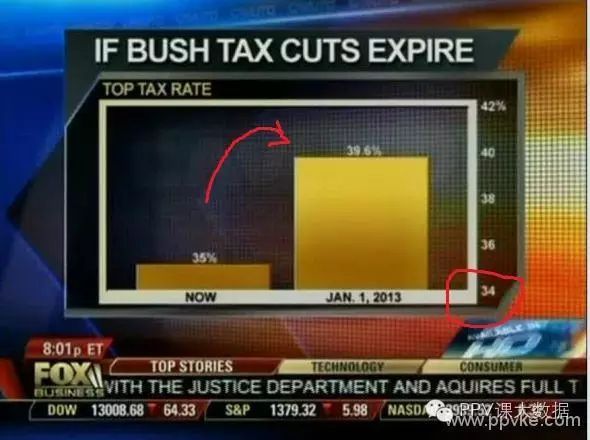
圖14a:福克斯新聞上的一個誤導性條形圖的例子
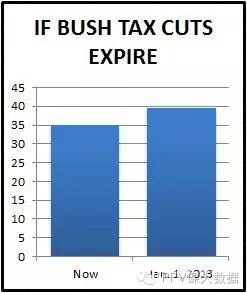
圖14b:如何客觀地呈現相同的數據 來自5 Ways to Avoid Being Fooled By Statistics
作者經常試圖隱藏他們研究中的不足,通過精明的講故事和省略重要細節,跳到提出誘人的錯誤見解。因此,用拇指法則確定文章包含誤導統計推斷,就是檢 查這篇文章是否包含了統計方法,和統計方法相關的選擇上的細節限制。找一些關鍵詞如「樣本」「誤差」等等。雖然關於什麼樣的樣本大小或誤差是合適的沒有完 美的答案,但這些屬性一定要在閱讀結果的時候牢記。
首先,一篇可靠的文章必須沒有任何未經證實的主張。所有的觀點必須有過去的研究的支持。否則,必須明確將其區分為「意見」,而不是一個觀點。其次, 僅僅因為一篇文章是著名的研究論文,並不意味著它是使用適當的研究方向的論文。這可以通過閱讀這些稱為研究論文「全部」,和獨立判斷他們的相關文章來驗 證。最後,雖然最終結果可能看起來是最有趣的部分,但是通常是致命地跳過了細節研究方法(和發現錯誤、偏差等)。
理想情況下,我希望所有這類文章都發表他們的基礎研究數據方法。這樣,文章可以實現真正的可信,每個人都可以自由分析數據和應用研究方法,自己得出結果。
Q15解釋Edward Tufte「圖表垃圾」的概念。
回答者:Gregory Piatetsky
圖標垃圾指的是所有的圖表和圖形視覺元素沒有充分理解表示在圖上的信息,或者沒有引起觀看者對這個信息的注意。
圖標垃圾這個術語是由Edward Tufte在他1983年的書《定量信息的視覺顯示》里提出的。
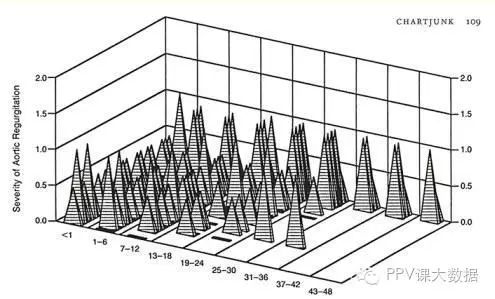
圖15所示。Tufte寫道:「一種無意的Necker錯覺,兩個平面翻轉到前面。一些金字塔隱藏其他;一個變數(愚蠢的金字塔的堆疊深度)沒有標籤或規模。」
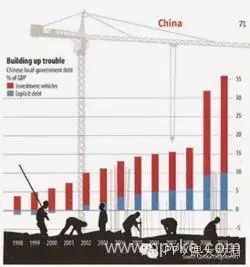
圖標垃圾的更現代的例子,很難理解excel使用者畫出的柱狀圖,因為「工人」和「起重機」掩蓋了他們。
這種裝飾的問題是,他們迫使讀者更加困難而非必要地去發現數據的含義。
Q16你會如何篩查異常值?如果發現它會怎樣處理?
回答者:Bhavya Geethika.
篩選異常值的方法有z-scores, modified z-score, box plots, Grubb』s test,Tietjen-Moore測試指數平滑法,Kimber測試指數分佈和移動窗口濾波演演算法。然而比較詳細的兩個方法是:Inter Quartile RangeAn outlier is a point of data that lies over 1.5 IQRs below the first quartile (Q1) or above third quartile (Q3) in a given data set.
High = (Q3) + 1.5 IQR
Low = (Q1) – 1.5 IQR
Tukey Method
It uses interquartile range to filter very large or very small numbers. It is practically the same method as above except that it uses the concept of 「fences」. The two values of fences are:
Low outliers = Q1 – 1.5(Q3 – Q1) = Q1 – 1.5(IQR)
High outliers = Q3 + 1.5(Q3 – Q1) = Q3 + 1.5(IQR)
在這個區域外的任何值都是異常值
當你發現異常值時,你不應該不對它進行一個定性評估就刪除它,因為這樣你改變了數據,使其不再純粹。重要的是要在理解分析的背景下或者說重要的是「為什麼的問題——為什麼異常值不同於其他數據點?」
這個原因是至關重要的。如果歸因於異常值錯誤,你可能把它排除,但如果他們意味著一種新趨勢、模式或顯示一個有價值的深度數據,你應該保留它。
Q17如何使用極值理論、蒙特卡洛模擬或其他數學統計(或別的什麼)正確估計非常罕見事件的可能性?
回答者:Matthew Mayo.
極值理論(EVT)側重於罕見的事件和極端,而不是經典的統計方法,集中的平均行為。EVT的州有3種分佈模型的極端數據點所需要的一組隨機觀察一些地理分佈:Gumble,f,和威布爾分佈,也稱為極值分佈(EVD)1、2和3分別。
EVT的狀態,如果你從一個給定的生成N數據集分佈,然後創建一個新的數據集只包含這些N的最大值的數據集,這種新的數據集只會準確地描述了EVD分佈之一:耿貝爾,f,或者威布爾。廣義極值分佈(GEV),然後,一個模型結合3 EVT模型以及EVD模型。
知道模型用於建模數據,我們可以使用模型來適應數據,然後評估。一旦發現最好的擬合模型,分析其執行,包括計算的可能性。
Q18推薦引擎是什麼?它如何工作?
回答者:Gregory Piatetsky
現在我們很熟悉Netflix——「你可能感興趣的電影」或亞馬遜——購買了X產品的客戶還購買了Y的推薦。
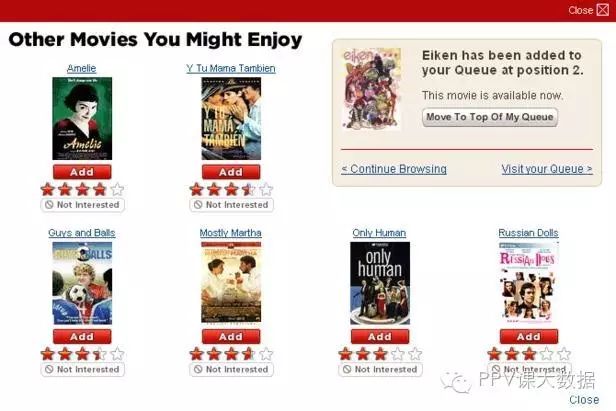
你可能感興趣的電影
這樣的系統被稱為推薦引擎或廣泛推薦系統。
他們通常以下兩種方式之一產生推薦:使用協作或基於內容的過濾。
基於用戶的協同過濾方法構建一個模型過去的行為(以前購買物品,電影觀看和評級等)並使用當前和其他用戶所做的決定。然後使用這個模型來預測(或評級)用戶可能感興趣的項目。
基於內容的過濾方法使用一個項目的特點推薦額外的具有類似屬性的物品。這些方法往往結合混合推薦系統。
這是一個比較,當這兩種方法用於兩個流行音樂推薦系統——Last.fm 和 Pandora Radio。(以系統推薦條目為例)
Last.fm創建一個「站」推薦的歌曲通過觀察樂隊和個人定期跟蹤用戶聽和比較這些聽其他用戶的行為。最後一次。fm會跟蹤不出現在用戶的圖書館,但通常是由其他有相似興趣的用戶。這種方法充分利用了用戶的行為,它是一個協同過濾技術。
Pandora用一首歌的屬性或藝術家(400年的一個子集屬性提供的音樂基因工程)以設定具有類似屬性的「站」,播放音樂。用戶的反饋用來提煉的結果,排除用戶「不喜歡」特定的歌曲的某些屬性和強調用戶「喜歡」的歌的其他屬性。這是一個基於內容的方法。
這裡有一些很好的介紹Introduction to Recommendation Engines by Dataconomy 和an overview of building a Collaborative Filtering Recommendation Engine by Toptal。關於推薦系統的最新研究,點擊ACM RecSys會議。
Q19解釋什麼是假陽性和假陰性。為什麼區分它們非常重要?
回答者:Gregory Piatetsky
在二進位分類(或醫療測試)中,假陽性是當一個演演算法(或測試)滿足的條件,在現實中不滿足。假陰性是當一個演演算法(或測試)表明不滿足一個條件,但實際上它是存在的。
在統計中,假設檢驗出假陽性,也被稱為第一類誤差和假陰性- II型錯誤。
區分和治療不同的假陽性和假陰性顯然是非常重要的,因為這些錯誤的成本不一樣。
例如,如果一個測試測出嚴重疾病是假陽性(測試說有疾病,但人是健康的),然後通過一個額外的測試將會確定正確的診斷。然而,如果測試結果是假陰性(測試說健康,但是人有疾病),然後患者可能會因此死去。
Q20你使用什麼工具進行可視化?你對Tableau/R/SAS(用來作圖)有何看法?如何有效地在一幅圖表(或一個視頻)中表示五個維度?
回答者:Gregory Piatetsky
有很多優秀的數據可視化工具。R,Python,Tableau和Excel數據科學家是最常用的。
這裡是有用的KDnuggets資源:
可視化和數據挖掘軟體
Python可視化工具的概述
21個基本數據可視化工具
前30名的社交網路分析和可視化工具
標籤:數據可視化
有很多方法可以比二維圖更好。第三維度可以顯示一個三維散點圖,可以旋轉。您可以操控顏色、材質、形狀、大小。動畫可以有效地用於顯示時間維度(隨時間變化)。
這是一個很好的例子。
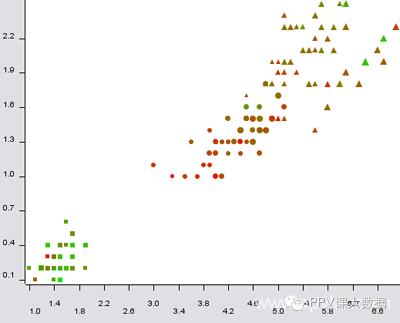
圖20:五維虹膜數據的散點圖,尺寸:花萼長度;顏色:萼片寬;形狀:類;x-column:花瓣長度;y-column:花瓣寬度。
從5個以上的維度,一種方法是平行坐標,由Alfred Inselberg首先提出。
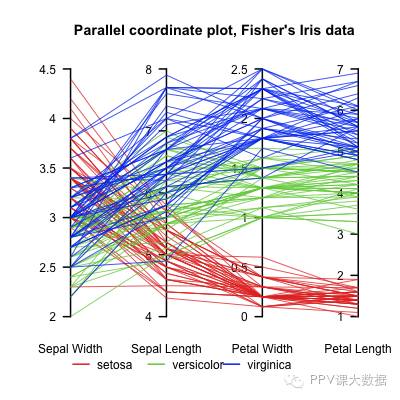
圖20 b:平行坐標里的虹膜數據 |
|





 狗仔卡
狗仔卡





 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 搶沙發
搶沙發 樓主
樓主