|
|
2019-02-15 17:22開發/視頻/技術
自從卷積神經網路在特定的圖像識別任務上開始超越人類以來,計算機視覺領域的研究一直在飛速發展。
CNN(或ConvNets)的基本架構是在20世紀80年代開發的。Yann LeCun在1989年通過使用反向傳播訓練模型識別手寫數字,改進了最初的設計。
自那以後,這個領域取得了長足的進步。
在2018年,我們看到計算機視覺領域出現了許多新穎的架構設計,這些設計改進性能基準,也擴大了機器學習的模型可以分析的媒介範圍。
在圖像生成方面,我們也看到了一些突破,包括逼真的風格轉換、高解析度的圖像生成和視頻到視頻的合成。
我們在不久前總結了2018年的較高級機器學習論文。由於計算機視覺和圖像生成對於AI應用的重要性和普及性,本文中,我們總結了2018年最重要的10篇視覺相關的研究。
以下是我們精選的2018必讀計算機視覺論文Top 10:
Spherical CNNs
Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
A Closed-form Solution to Photorealistic Image Stylization
Group Normalization
Taskonomy: Disentangling Task Transfer Learning
Self-Attention Generative Adversarial Networks
GANimation: Anatomically-aware Facial Animation from a Single Image
Video-to-Video Synthesis
Everybody Dance Now
Large Scale GAN Training for High Fidelity Natural Image Synthesis
1、 球形CNN
標題:Spherical CNNs
作者:Taco S. Cohen, Mario Geiger, Jonas Koehler, Max Welling
https://arxiv.org/abs/1801.10130
論文摘要
卷積神經網路(CNN)可以很好的處理二維平面圖像的問題。然而,對球面圖像進行處理需求日益增加。例如,對無人機、機器人、自動駕駛汽車、分子回歸問題、全球天氣和氣候模型的全方位視覺處理問題。將球形信號的平面投影作為卷積神經網路的輸入的這種天真做法是註定要失敗的,因為這種投影引起的空間扭曲會導致CNN無法共享權重。
這篇論文介紹了球形CNN的基本構建塊。我們提出了利用廣義傅里葉變換(FFT)進行快速群卷積(互相關)的操作。我們證明了球形CNN在三維模型識別和分子能量回歸分析中的計算效率、數值精度和有效性。
概要總結
汽車、無人機和其他機器人使用的全向攝像機能夠捕捉到它們周圍環境的球形圖像。我們可以通過將這些球形信號投射到平面上並使用CNN來分析它們。然而,球形信號的任何平面投影都會導致失真。為了解決這個問題,來自阿姆斯特丹大學的研究小組引入了球形CNN的理論,這種網路可以分析球形圖像,而不會被扭曲所欺騙。該方法在3D形狀和球形MNIST圖像的分類以及分子能量回歸分析(計算化學中的一個重要問題)中都有很好的效果。
核心思想
球形信號的平面投影會導致嚴重的失真,因為有些區域看起來比實際面積大或小。
傳統的CNN對於球形圖像來說是無效的,因為當物體在球體周圍移動時,它們也會出現收縮和拉伸(試想一下,地圖上格陵蘭島看起來比它實際要大得多)。
解決方案是使用球形CNN,它對輸入數據中的球形旋轉具有穩健性。球形神經網路通過保持輸入數據的原始形狀,平等地對待球面上的所有對象而不失真。
最重要的成果
提出了構建球形CNN的數學框架。
提供了易於使用、快速且內存高效的PyTorch代碼來實現這些CNN。
為球形CNN在旋轉不變學習問題中的應用提供了第一個經驗支持:
球形MNIST圖像的分類
3D形狀分類,
分子能量回歸分析。
AI社區的評價
這篇論文獲得了ICLR 2018年的較佳論文獎,ICLR是一個領先的機器學習會議。
未來研究方向
為球體開發一個可操縱的CNN來分析球體上向量束的截面(例如,風向)。
將數學理論從2D球面擴展到3D點雲,用於在反射和旋轉下不變的分類任務。
可能的應用
能夠分析球面圖像的模型可以應用於以下問題:
無人機、機器人和自動駕駛汽車的全向視覺;
計算化學中的分子回歸問題
全球天氣和氣候模型。
代碼
作者在GitHub上提供了這篇論文的原始實現:
https://github.com/jonas-koehler/s2cnn
2、同時愚弄視覺系統和人類的對抗樣本
標題:Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
作者:Gamaleldin F. Elsayed, Shreya Shankar, Brian Cheung, Nicolas Papernot, Alex Kurakin, Ian Goodfellow, Jascha Sohl-Dickstein
https://arxiv.org/abs/1802.08195
論文摘要
機器學習模型很容易受到對抗性樣本(adversarial examples)的影響:圖像中的微小變化會導致計算機視覺模型出錯,比如把一輛校車誤識別成鴕鳥。然而,人類是否容易犯類似的錯誤,這仍然是一個懸而未決的問題。在這篇論文中,我們通過利用最近的技術來解決這個問題,這些技術可以將具有已知參數和架構的計算機視覺模型轉換為具有未知參數和架構的其他模型,並匹配人類視覺系統的初始處理。我們發現,在計算機視覺模型之間強烈轉移的對抗性樣本會影響有時間限制的人類觀察者做出的分類。
概要總結
谷歌大腦的研究人員正在尋找這個問題的答案:那些不是特定於模型的對抗樣本,並且可以在不訪問模型的參數和架構的情況下欺騙不同的計算機視覺模型,是否同時也可以欺騙有時間限制的人類?他們利用機器學習、神經科學和心理物理學的關鍵思想,創造出對抗性樣本,這些樣本確實在時間有限的設置下影響人類的感知。因此,這篇論文介紹了一種人類和機器之間共享的錯覺。

核心思想
在第一步中,研究人員使用黑盒對抗性樣本構建技術,在不訪問模型架構或參數的情況下創建對抗性示例。
然後,他們調整計算機視覺模型來模擬人類最初的視覺過程,包括:
在每個模型前面加上視網膜層,視網膜層對輸入進行預處理,從而結合人眼執行的一些轉換;
對圖像進行偏心依賴的模糊處理,以接近受試者的視覺皮層通過其視網膜晶格接收到的輸入。
人類的分類決策在一個有時間限制的環境中進行評估,以檢測人類感知中的細微影響。
最重要的成果
表明在計算機視覺模型之間傳遞的對抗性樣本也成功地影響了人類的感知。
證明了卷積神經網路與人類視覺系統的相似性。
AI社區的評價
這篇論文在AI社區得到廣泛討論。儘管大多數研究人員對這些結果感到震驚,但一些人認為,我們需要對對抗性圖像進行更嚴格的定義,因為如果人類將受到干擾的貓圖像歸類為狗,那麼它很可能已經是狗,而不是貓了。
未來研究方向
研究哪些技術對於將對抗性樣本轉移到人類身上是至關重要的(視網膜預處理,模型集成)。
可能的應用
從業者應該考慮這樣一種風險,即圖像可能被操縱,導致人類觀察者產生不尋常的反應,因為對抗性樣本可能會在我們意識不到的情況下影響我們。
3、照片級逼真的圖像風格化
標題:A Closed-form Solution to Photorealistic Image Stylization
作者:Yijun Li, Ming-Yu Liu, Xueting Li, Ming-Hsuan Yang, Jan Kautz
https://arxiv.org/abs/1802.06474
論文摘要
照片級逼真的圖像風格化涉及到將參考照片的風格轉換為內容照片,其約束條件是,經過風格化的照片應保持照片級逼真程度。雖然存在多種逼真的圖像風格化方法,但它們往往會產生具有明顯偽影的空間不一致。在這篇論文中,我們提出一種解決這些問題的方法。
該方法由風格化步驟(stylization step)和平滑步驟(smoothing step)組成。當風格化步驟將引用照片的樣式轉換為內容照片時,平滑步驟確保空間上一致的樣式化。每個步驟都有一個封閉的解決方案,可以有效地計算。我們進行了廣泛的實驗驗證。結果表明,與其他方法相比,該方法生成的逼真風格輸出更受受試者的青睞,同時運行速度更快。源代碼和其他結果可在https://github.com/NVIDIA/FastPhotoStyle獲得。
概要總結
英偉達(NVIDIA)和加州大學默塞德分校的研究團隊提出了一種新的解決照片級圖像風格化的方法——FastPhotoStyle。該方法包括兩個步驟:風格化和平滑化。大量的實驗表明,該方法生成的圖像比以前的較先進的方法更真實、更引人注目。更重要的是,由於採用封閉式的解決方案,FastPhotoStyle生成風格化圖像的速度比傳統方法快49倍。

核心思想
照片級真實的圖像風格化的目標是在保持輸出圖像逼真的同時,將參考照片的風格轉換為內容照片。
任務分為風格化和平滑化兩個步驟:
風格化步驟是基於增白和著色變換(WCT),通過特徵投影處理圖像。然而,由於WCT是為藝術圖像的風格化而開發的,因此,它常常會生成用於照片級真實圖像風格化的結構構件。為了解決這個問題,本文引入了PhotoWCT方法,將WCT中的上採樣層替換為非池化層,從而保留了更多的空間信息。
平滑步驟用於解決第一步之後可能出現的空間不一致的樣式。平滑基於流形排序演算法。
這兩個步驟都具有封閉形式的解決方案,這意味著可以通過固定數量的操作(即,卷積、較大池化、增白等)。因此,計算比傳統方法更有效。
最重要的成果
提出了一種新的圖像風格化化方法:FastPhotoSyle,其中:
通過渲染更少的結構偽影和不一致樣式,從而比藝術風格化演算法表現更好;
通過不僅合成風格照片中色彩,而且合成風格照片的圖案,從而優於照片級真實的風格化演算法。
實驗表明,在風格化化效果(63.1%)和光真實感(73.5%)方面,用戶更喜歡FastPhotoSyle的結果,而不是之前的較先進的技術。
FastPhotoSyle可以在13秒內合成一張解析度為1024 x 512的圖像,而之前較先進的方法需要650秒才能完成相同的任務。
AI社區的評價
該論文在歐洲計算機視覺會議ECCV 2018上發表。
未來研究方向
找到一種從風格照片遷移小圖案的方法,因為這篇論文提出的方法可以將它們平滑化。
探索進一步減少風格化照片中的結構偽影數量的可能性。
可能的應用
內容創建者可以從照片級真實的圖像風格化技術中獲得很大的好處,因為該技術基本上允許你根據適合的內容自動更改任何照片的風格。
攝影師們也將受到這項技術的影響。
代碼
NVIDIA團隊提供了該論文在GitHub上的原始實現:
https://github.com/NVIDIA/FastPhotoStyle
4、Group Normalization
標題:Group Normalization
作者:吳育昕, 何愷明
https://arxiv.org/abs/1803.08494
論文摘要
批標準化(Batch Normalization, BN)是深度學習進展中的一項里程碑式技術,它使各種網路都能進行訓練。但是,沿batch dimension進行標準化會帶來一些問題——由於批統計估計不準確,當batch size變小時,BN的誤差會迅速增大。這限制了BN用於訓練更大模型和將特徵遷移到計算機視覺任務(包括檢測、分割和視頻)的用途,這些任務受內存消耗限制,需要小的batch size。
在這篇論文中,我們提出了組標準化(Group Normalization ,GN),作為BN的簡單替代。GN將通道劃分為組,並在每個組內計算均值和方差以進行標準化。GN的計算獨立於batch sizes,在各種範圍的batch sizes精度穩定。
在ImageNet上訓練的ResNet-50,當batch size 為2時,GN的誤差比BN小10.6%;在使用典型 batch size時,GN與BN一般好,並且優於其他標準化變體。此外,GN可以很自然地從預訓練過渡到 fine-tuning。GN在COCO的目標檢測和分割任務,以及在Kinetics的視頻分類任務中都優於基於BN的同類演算法,這表明GN可以在各種任務中有效地替代強大的BN。GN可以通過現代庫中的幾行代碼輕鬆實現。
概要總結
Facebook AI研究團隊建議使用Group Normalization (GN)代替Batch Normalization (BN)。這篇論文的作者是FAIR的吳育昕和何愷明,他們認為,對於small batch sizes,BN的錯誤會急劇增加。這限制了BN的使用,因為當使用大型模型來解決計算機視覺任務時,由於內存限制而需要小的batch sizes。相反,Group Normalization與batch sizes無關,因為它將通道劃分為組,並計算每個組內標準化的均值和方差。實驗證實,GN在目標檢測、分割、視頻分類等多種任務中都優於BN。
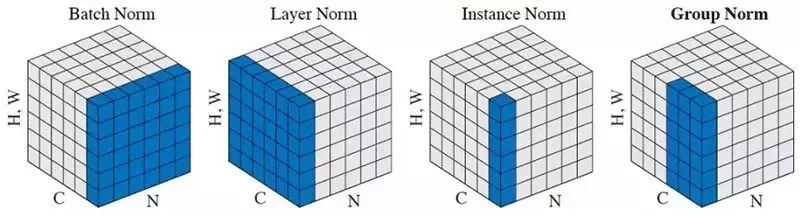
核心思想
Group Normalization是Batch Normalization的一個簡單替代方法,特別是在batch size較小的場景中,例如需要高解析度輸入的計算機視覺任務。
GN只探索層的維數,因此它的計算是獨立於batch size的。具體地說,GN將通道或特徵映射劃分為組,並在每個組內對特徵標準化。
Group Normalization可以通過PyTorch和TensorFlow中的幾行代碼輕鬆實現。
最重要的成果
提出了Group Normalization,一種新的有效的歸一化方法。
評估了GN在各種應用中的表現,並表明:
GN的計算獨立於batch sizes,在大範圍的batch sizes中精度穩定。例如,對於batch size為2的ImageNet訓練的ResNet-50, GN的錯誤率比基於BN的模型低10.6%。
GN也可以轉移到fine-tuning。實驗表明,在COCO數據集的目標檢測和分割任務,以及Kinetics數據集的視頻分類任務,GN優於BN。
AI社區的評價
該論文在ECCV 2018上獲得了較佳論文提名。
根據Arxiv Sanity Preserver,這篇論文也是2018年第二受歡迎的論文。
未來研究方向
將group normalization應用到序列模型或生成模型。
研究GN在強化學習的學習表示方面的表現。
探索GN與合適的正則化項相結合能否改善結果。
可能的應用
依賴基於BN的模型進行對象檢測、分割、視頻分類和其他需要高解析度輸入的計算機視覺任務的應用可能會受益於基於GN的模型,因為它們在這些設置中更準確。
代碼
FAIR團隊提供Mask R-CNN基線結果和使用Group normalize訓練的模型:
https://github.com/facebookresea ... /master/projects/GN
GitHub上也提供了使用PyTorch實現的group normalization:
https://github.com/chengyangfu/pytorch-groupnormalization
5、分解任務遷移學習
標題:Taskonomy: Disentangling Task Transfer Learning
By Amir R. Zamir,Alexander Sax,William Shen,Leonidas J. Guibas,Jitendra Malik,Silvio Savarese(2018)
https://arxiv.org/abs/1804.08328
論文摘要
視覺任務之間有關聯嗎?例如,表面法線可以簡化對圖像深度的估計嗎?直覺回答了這些問題,暗示了視覺任務中存在結構。了解這種結構具有顯著的價值;它是遷移學習的基本概念,提供了一種原則性的方法來識別任務之間的冗餘。
我們提出了一種完全計算的可視化任務空間結構建模方法。 這是通過在潛在空間中的二十六個2D,2.5D,3D和語義任務的字典中查找(一階和更高階)傳遞學習依賴性來完成的。該產品是用於任務遷移學習的計算分類映射。我們研究這種結構的結果,例如出現的非平凡關係,並利用它們來減少對標記數據的需求。例如,我們展示了在保持性能幾乎相同的情況下,解決一組10個任務所需的標記數據點的總數可以減少大約2/3(與獨立訓練相比)。我們提供了一組用於計算和探測這種分類結構的工具,包括一個解決程序,用戶可以使用它來為他們的用例設計有效的監督策略。
概覽
自現代計算機科學的早期以來,許多研究人員就斷言視覺任務之間存在一個結構。現在Amir Zamir和他的團隊試圖找到這個結構。他們使用完全計算的方法建模,並發現不同可視化任務之間的許多有用關係,包括一些重要的任務。他們還表明,通過利用這些相互依賴性,可以實現相同的模型性能,標記數據要求大約減少2/3。
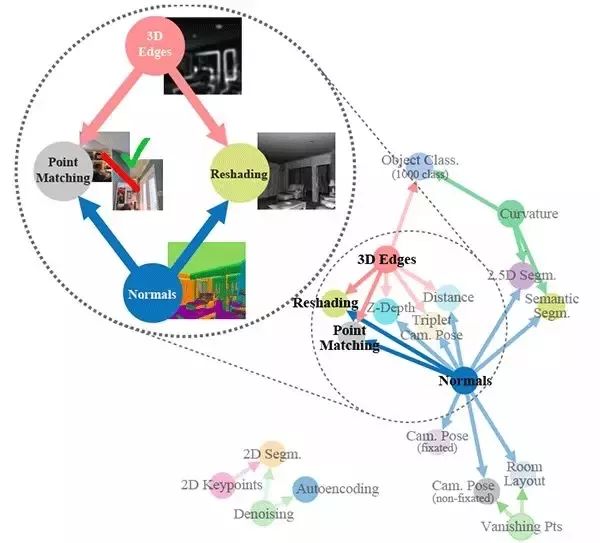
核心思想
了解不同可視化任務之間關係的模型需要更少的監督、更少的計算和更可預測的行為。
一種完整的計算方法來發現視覺任務之間的關係是可取的,因為它避免了強加的、可能是不正確的假設:先驗來自於人類的直覺或分析知識,而神經網路可能在不同的原理上運作。
最重要的成果
識別26個常見視覺任務之間的關係,如目標識別、深度估計、邊緣檢測和姿態估計。
展示這個結構如何幫助發現對每個視覺任務最有效的遷移學習類型。
AI社區的評價
該論文在計算機視覺與模式識別重要會議CVPR 2018上獲得了較佳論文獎。
結果非常重要,因為對於大多數實際任務,大規模標記數據集不可用。
|
|





 狗仔卡
狗仔卡




 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 搶沙發
搶沙發 樓主
樓主