







- 更可怕的病毒 [2020/01]
- 陳破空欠考慮 [2020/01]
- 策略與機遇 [2020/03]
- 亂世也要生存 [2019/11]
- 權本主義----手機 [2023/09]
- 麻雀雖小,五臟俱全 [2019/06]
- 習近平的選擇 [2019/12]
- 范冰冰VS趙家人 [2018/10]
- 川普為何屢贊習近平? [2020/02]
- 中國芯 [2018/04]
- 說繪畫 [2020/10]
- 談愛國 [2019/07]
- 換個角度看香港 [2019/08]
- 神秘的基尼係數 [2017/06]
- 澳洲高校風雲 [2017/08]
- 無法融入國際社會的中共 [2019/09]
- 世界新秩序 [2024/12]
- 漢語是終極解決 [2025/10]
- 語言的數理邏輯(3)語法的歷史 [2025/10]
如今,討論人工智慧的文字鋪天蓋地。但是,有一個最關鍵的問題,所有人都避而不談。這就是,關於大腦與信息鏈接的問題。雖然有人聲稱,可以用電腦直接與大腦鏈接,但是,即便鏈接后的信號,也需要變成文字才能進行思考。維特根斯坦說:「我的語言邊界就是我思想的邊界。」沒有變成語言的思想類似莊子所說,沒有感官的混沌。
在人腦記憶能力與海量的信息之間,英語存在著一個無法逾越的困境。唯獨漢語能夠解決這個問題。從ChatGPT上查得,目前的英語單詞數量,在15到200萬之間。但一個人能夠記住的單詞只有2萬到3萬之間。無論AI如何發展,人類通過英語能夠享受到的信息只能小於總量的3/15=1/5。隨著世界信息量的增加,這個數值將無限縮小。只有漢語能夠解決這個問題。
一個普通話使用者,掌握三千五百個漢字,就能夠掌握世界上所有的信息,或者說能夠掌握到超過200萬單詞所負載的信息。原因是什麼?下表告訴你答案。
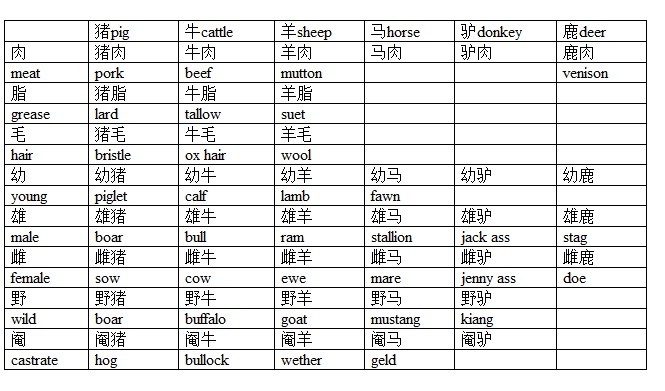
從表中看出,漢語的單詞是由兩個漢字組成的。比如「羊脂」而英語的「羊」是sheep,「脂」是grease,羊脂是suet,三者之間,沒有推導關係。或者說,你學了羊字,學了脂字,但還必須學會「羊脂」suet以後,才能用它來交流。一個中國人,學會了上表中最左一列,以及最上面一行漢字后,就能自己總結出上表中其他部分的單詞,而英語使用者卻需要將表中所有的單詞都學會,才能用這些單詞交流。這就是為什麼漢語使用者,只要記住3500個漢字,就相當於英語使用者記住上百萬單詞的原因。
假設每個漢字都能兩兩組成單詞的話,那麼3500個漢字能夠組成3500X3500=12250000個單詞。如果每三個漢字都能組成一個單詞,那麼,其結果將是天文數字。讀者可以自己演算一下。
幾乎在每一個英語論壇中,我都曾經遇到過這樣的問題,為什麼只有漢字可以進行這樣的組合,英語卻不成呢?答案是,漢語使用了聲調,而英語忽略了這個聲音信息。我們知道,一種語言的推廣,首先是聲音的推廣,其次才是文字出現。如果聲音的基本數量達不到要求,那麼,這種語言的文字無論怎樣改變,也不會使人增加記憶。
舉例來說,電腦使用的是二進位語言。如果用聲音來處理,它應該只有,兩個聲音。我們假設將它設定為A和B。僅憑它倆,只能表達兩件事物。如果我們用兩個符號代表一件事物,它倆就能表達最多四件事物。分別是AA,AB,BA,BB。從這裡看出,雖然表達的事物增加了一倍,但是,使用者每次卻需要消耗兩倍的時間來表達一件事物。接下來,我們如果需要表達400種不同的事物,用AB語言來表達,就需要9個聲音的組合,或者說九倍的時間來表達每一件事物。因為2的9次方是512>400。英語大約有400種聲音,如果表達的事物只有四百種,那麼,英語可以用任何單一的聲音,表達一種事物,而AB語言則必須用九個聲音的組合來表達400種事物之一。它比英語慢了9倍。
同理,漢語的普通話的基本聲音種類大約700個,每一個都可以變成四聲,這就是說,漢語的基本生意大約2800個(實則2500個左右)這就使得漢語在表達的時候,可以使用兩兩的組合來組詞,不至於混淆,此外,漢語的部首也幫助它擺脫不少同音詞的混淆。相反,英語沒有部首,而發音總量又不夠用,因此,必須選擇任何還沒有被利用的發音組合來表達一個新的意思。
除了組成文字需要的基本符號以外,聲音種類多的語言還有其他的優點。第一,如果你一輩子使用AB語言,那麼,一輩子活下來,你享受到的所有信息,最大可能也就是英語的九分之一。也就是說,後者的思想邊界比前者大了九倍。第二,思維是語言在大腦中的運動。當你的運動速度是另一種語言的九分之一的時候,你的思維速度怎能趕得上另一種語言。
忽略了語言學的問題。漢語是記住數千漢字后就能享受網上所有的信息。而英語做到這一點則需要記住數百萬單詞。兩者對比,不是困難與容易的區別,而是能與不能的差異。新技術的發展,將這個問題變得更加突出。本文就是通過計算來討論它的原因。
最後,還要說一點,一旦人工智慧解決了翻譯問題以後,普通話使用者的將以最少的記憶,獲得最多的知識。
- [03/01]人間北看成南
- [03/13]對於川普的評價
- [07/04]從2024年諾貝爾經濟學獎看世界教育體系的衰落
- [08/03]基極(三極體)理論
- [09/15]查理柯克是種族主義嗎?
- [10/01] 漢語是終極解決
- [10/14]語言的數理邏輯(1)
- [10/16]語言的數理邏輯(2) 英語的語法就是漢語的病句
- [10/21]語言的數理邏輯(3)語法的歷史
發表評論 評論 (17 個評論)

- 回復 Wuming123
- 你就是個逢中必反的二五仔!中文利於計算機處理,這都是成了定論的東西,你也能變著法的潑一瓢污水!
浮平: 利弊兼并。一字多意,一意多字,片語多樣,涵義多重;既有情感表達的豐富,主觀解讀的便利,又存在定義概念模糊,邏輯推理粗糙,是非價值混亂,結論自相矛盾的困

- 回復 浮平
- 用腳投票,用腦投機,用心害人,用口表忠,這類低層次大外宣永遠理解不了邏輯規律,只能停留在擁啊擁反啊反的哲政混合一鍋粥的二維認知水平。多上網看評論也是一個學習邏輯基礎和提升理性分析的機會。
Wuming123: 你就是個逢中必反的二五仔!中文利於計算機處理,這都是成了定論的東西,你也能變著法的潑一瓢污水!

- 回復 蘇誠忠
- 不明白您說的是什麼意思。我原文的意思是,當一種語言中的聲音種類增加時,記憶的比重下降,因此可以使得更多的單詞不必記憶,僅用推理的方式就能理解,或者運用。最簡單的例子就是一種最簡單的語言,只有兩種聲音,好比A和B,像電腦一樣。這種語言依然可以表達整個宇宙的事物。但缺點是,速度太慢。比英語更慢,英語有400種不同的聲音。如果,有400種事物需要用英語來表達,那麼,英語用每一種聲音便可以表達一件事物。但AB語言必須用9個聲音的組合來表達400種事物之一。因為2的9次方大於400英語發音一次就解決的問題,AB語言需要發音9次。是不是效率降低了9倍?一輩子活下來。AB語言的使用者,只能享受到英語使用者9分之一的信息。
浮平: 利弊兼并。一字多意,一意多字,片語多樣,涵義多重;既有情感表達的豐富,主觀解讀的便利,又存在定義概念模糊,邏輯推理粗糙,是非價值混亂,結論自相矛盾的困
- 回復 蘇誠忠
- AI的確無法幫助人類將一個畫面,或者感官變成單詞或者文字。變不成文字的一段思想僅僅是一團亂麻。所以,維特根斯坦說:我語言的界限就是我思想的界限。也就是說,一個感官感覺到的東西,無法與人類語言進行有效的溝通。
閑言碎語: 看不懂,AI的功能可以打敗人腦,為什麼還不可以幫助人腦記住幾千和幾十萬個字?不應該有區別。漢語有很多字都沒有,必須要借鑒外來語。
- 回復 蘇誠忠
- 相對於拼音文字而言,中文不利於鍵盤輸入,因此,上個世紀,取消漢字的聲音不絕於耳。但是,時代變了,漢字有利於語音輸入,它語音輸入的速度遠遠大於拼音文字。
Wuming123: 你就是個逢中必反的二五仔!中文利於計算機處理,這都是成了定論的東西,你也能變著法的潑一瓢污水!
- 回復 蘇誠忠
- 我的邏輯是建立在數學推導的基礎之上的。在正常的說話時,人類每發一個聲音就需要消耗250毫秒。一種含有400種聲音的語言,在這個時間內,能夠從400種事物中選出一個來。而在相同的時間內,一個只有兩種聲音的語言,僅能從兩種事物中選出一個來。漢語普通話使用了四聲,因此,比英語的聲音種類至少多了四倍,所以,漢語表達的能力更強。
浮平: 用腳投票,用腦投機,用心害人,用口表忠,這類低層次大外宣永遠理解不了邏輯規律,只能停留在擁啊擁反啊反的哲政混合一鍋粥的二維認知水平。多上網看評論也是一
- 回復 浮平
- 信息傳遞不需要依賴更多的基礎表達元,少量音素通過組合就能表達無限內容。多音素語言未必能讓信息傳遞更高效,關鍵在組合與規則,而不是聲音的多少。
蘇誠忠: 不明白您說的是什麼意思。我原文的意思是,當一種語言中的聲音種類增加時,記憶的比重下降,因此可以使得更多的單詞不必記憶,僅用推理的方式就能理解,或者運用
- 回復 蘇誠忠
- 電腦使用二進位制,就相當是兩個聲音輸入。前蘇聯直到當今俄羅斯都希望用三進位制進行計算。但是,硬體不允許,因為電壓無法保證。為什麼這是所有人都夢想?就因為增加一個符號可以大大加快計算速度。它的好處不比晶元尺寸縮小差多少。同樣的道理,漢語比英語在理論上至少多了四倍的聲音,因此,其傳遞速度,思維速度以及一生中能夠享受信息的總量都遠超英語,這不是「未必」的事情,而是一定的事情,是計算的結果,不容否定。你到任何語言學論壇,信息技術論壇,或者是chatgpt上去問也都是這個答案。凡是懂得指數運算以及排列組合的人都不會弄錯的。
浮平: 信息傳遞不需要依賴更多的基礎表達元,少量音素通過組合就能表達無限內容。多音素語言未必能讓信息傳遞更高效,關鍵在組合與規則,而不是聲音的多少。
- 回復 浮平
- 舉個例子來說明音素與信息傳遞效率的關係 ---
蘇誠忠: 電腦使用二進位制,就相當是兩個聲音輸入。前蘇聯直到當今俄羅斯都希望用三進位制進行計算。但是,硬體不允許,因為電壓無法保證。為什麼這是所有人都夢想?就因
1)Encoding :利益 vs 禮儀,畜生 vs 出生 都有第一步因聲調不同,音素增加的方便,不需要進行兩者信息間的邏輯識別;但是,利益,立意;出生,出聲,初生,初升卻需要進一步邏輯識別。
2)Decoding: 權力、權利、全力,重陽、崇洋、崇陽,實力、勢力、事例、視力、勢利、市裡、十里、失利等等,首先需要對多音素進行邏輯識別才能準確傳遞信息。這是編碼部分便利與解碼複雜性並存的特徵。
- 回復 蘇誠忠
- 這話說到點子上了。同音詞的出現是漢語目前的一個缺陷。因為,普通話可以發出3432個聲音,而實際採用的卻只有1186個聲音;一個聲音包括一個聲母(輔音),一個韻母(母音)和一個聲調。普通話有22個聲母,39個韻母以及四聲,連乘22X39X4=3432,但實際的聲音沒有這麼多,因為,有些聲音發不出來。根據過去的一些研究,能夠發出來的至少有2500個。如果普通話進行一些改造,用2500個聲音來負載3500個漢字的話,那麼,同音詞的概率將大大降低。除此以外,部首也起到一定的區分功能。
浮平: 舉個例子來說明音素與信息傳遞效率的關係 ---
1)Encoding :利益 vs 禮儀,畜生 vs 出生 都有第一步因聲調不同,音素增加的方便,不需要進行兩者信息間的邏輯
- 回復 浮平
- 對了。這是三步邏輯推論曲 ---
蘇誠忠: 這話說到點子上了。同音詞的出現是漢語目前的一個缺陷。因為,普通話可以發出3432個聲音,而實際採用的卻只有1186個聲音;一個聲音包括一個聲母(輔音),一個韻
1)多音容易組成多音素,在邏輯上是成立的;
2)多音素在編碼中帶來部分方便,在邏輯上是成立的;
3)多音素在信息傳遞上一定帶來高效率的線性正比關係,在邏輯上是跳躍的。
- 回復 蘇誠忠
- 我說的聲音,不是音素。因素是指b,a,d,i,o等中的一個。我說的聲音是指能被別人聽到的,可以相互區分的聲音。發音和聽音都需要約250毫秒的時間。類似每個漢字所發的聲音。不是線性正比的關係吧,應該是按照指數的正比關係。可以說在邏輯上是混亂的,正是這個原因,任何人都能讓它負載任何意思,就好像二進位電腦的符號,本來沒有意義,經過人類的賦予,使它帶有了特殊的意義。
浮平: 對了。這是三步邏輯推論曲 ---
1)多音容易組成多音素,在邏輯上是成立的;
2)多音素在編碼中帶來部分方便,在邏輯上是成立的;
3)多音素在信息傳遞上一定帶
- 回復 浮平
- 您說的是聲調,也是廣義音素的元素,可通過發聲聽聲來識別。這與上面的邏輯分析結果不矛盾。
蘇誠忠: 我說的聲音,不是音素。因素是指b,a,d,i,o等中的一個。我說的聲音是指能被別人聽到的,可以相互區分的聲音。發音和聽音都需要約250毫秒的時間。類似每個漢字所發
- 回復 蘇誠忠
- 歷史上,最先出現的語音單位,是從古希臘人開始的。他們將含有一個母音的一組字母成為一個音節。我相信,這和他們最先發明母音字母有關。在他們之前,腓尼基人的字母中,沒有母音。因此,22個輔音字母只能發出22種聲音,到了希臘人手裡,他們發明了幾個母音,這樣一來,每個輔音就能與數個母音相結合發出熟貴聲音,大大的擴展了聲音的數量。但是,希臘人的單詞不可能是一輔一元的撰寫,那麼怎麼才能劃分聲音呢?只能按照音節劃分。也就是說left算是一個音節;一個母音外加周圍的所有的輔音。這樣的計算方法到了後來越來越不適應人們敘述的需要,於是出現了音素,也就是國際音標上的母音和輔音。這種計算方法依然無法進行計算。
浮平: 您說的是聲調,也是廣義音素的元素,可通過發聲聽聲來識別。這與上面的邏輯分析結果不矛盾。
蘇誠忠最受歡迎的博文
其它[文史雜談]博文更多
- 謝盛友:德國典雅小城薩爾費爾德Saalfeld
- bobzhou:50年代的調整教會學校和摧毀全國聖母軍組織
- 顧曉軍53:中國人政治啟蒙必讀的十本書(歐洲篇)
- change?:【名可名不可】嘉慶帝秀警惕 徐長卿羞御醫
- change?:九月之死,誰能接替他的位置?
- bobzhou:不要忽略中國幾乎所有的好醫院前身都是教會辦的醫院
- 蘇誠忠:查理柯克是種族主義嗎?
- bobzhou:這個法國神父保護了30多萬上海難民卻少有人知
- 8288:《半夜雞叫》的作者高玉寶臨終懺悔:「我心懷愧疚……」
- bobzhou:文革最慘痛的是對佛教的褻瀆和破壞
- 8288:《整人和被整,一個持續了半個世紀的輪迴》
- 8288:當年大批來華援建的烏克蘭專家,如今處境怎樣了??
- goofegg:作協和詩刊的盛宴及資本的狂歡
- 8288:一篇關於描寫上海的散文
- bobzhou:永遠不忘記八一八后全國的紅色恐怖和暴力行動
- 8288:歷史的先聲
- 黎民百姓:花甲之年,回記童期南京的文革始末場景
- 顧曉軍53:「川普愛上在白宮做保潔的我」
- 異域堂:海南「封關」變「離島」也在黨國卵翼下
- bobzhou:美國對中國抗日戰爭的支持和援助中的情況