







- 哈佛的故事:真假習明澤 [2015/04]
- 在美國如何免費看電視:ROKU好用嗎? [2013/10]
- 有史以來最蠢的哈佛學生? [2013/12]
- 華為思科的血海深仇是怎樣結下的? [2018/12]
- 付不起學費?美國上大學的省錢之道 [2013/09]
- 卡梅爾:尋找張大千在加州的足跡 [2019/01]
- 紐約哈萊姆區探秘 [2015/05]
- 在美國養個娃有多貴? [2015/01]
- 學鋼琴有用嗎? [2011/09]
- 斯坦福直線加速器SLAC探秘 [2015/09]
- 我們應該為孩子買房嗎? [2015/03]
- 選擇的負擔:我們為什麼要移民? [2014/10]
- 數學「諾貝爾獎」揭曉:又沒中國人啥事 [2014/09]
- 中國教育是世界第一嗎?從PISA考試談起 [2013/12]
- 好男人都死哪兒去啦? [2016/09]
- 家有才女 大事不好 [2011/12]
- 美國大選:投了也白投,白投也要投 [2012/10]
- 進村一周年感言:桃源夜話 [2012/06]
白露為霜注:五個月前當谷歌的計算機程序阿爾法圍棋(AlphaGo)擊敗歐洲圍棋冠軍樊麾二段時並沒有太多人在意,樊麾的段位不算高,也不是很有名。然而今年三月阿爾法圍棋同李世石之間的人機大戰卻完全不同,李九段雄居世界圍棋頂尖多年,名聲顯赫。這個在五個月前還不咋樣的計算機程序真有可能撼動人類頂尖的高手?絕大多數的人都認為是不可能的,李世石更是豪言要5:0取勝。
前天晚上第一場比賽吸引的眾多的觀眾,Youtube的錄像一天之內就有100萬人觀看。結果大出人意外,以李世石中盤認輸收場。對此,除了震驚之外很多棋迷還不服氣 - 李世石有些輕敵,或者選用不常見的開局是錯誤,等等。昨天晚上第二場比賽,AlphaGo持黑先行,李世石不敢大意,以較為常見的開局應對。局面一直非常膠著,黑棋氣勢站優,白棋拿實地穩紮穩打。中盤過後在現場用英文評論的Michael Redmond九段一遍又一遍地計算局面的得分,結論都是:很接近。突然,再算一遍后大驚失色:「黑棋領先了」。果然,不多久后李世石再次投子認輸。
0:2落後,李世石堪堪要敗,人類是不是快沒戲了?這的確是很好的問題。再往下還有三場比賽,李世石應該還是有機會的,但這個計算機程序具有擊敗人類的頂尖棋手的能力已經是不爭的事實。AlphaGo還不時下出精彩或出人意料的棋來,大有青出於藍而勝於藍的架式。
那麼阿爾法圍棋到底是何方神聖,它是怎樣能進步如此神速呢?今年一月,谷歌的研究團隊發了一篇博文,介紹阿爾法圍棋所用的演算法和策略。這篇博文來得正是時候,我把它翻譯成中文,也可以讓那些被驚呆的棋迷死個的明白。
其實大多數人不懂「黑暗」的力量有多麼強大。擊敗李世石的AlphaGo多機分佈系統動用了1202個CPU和176個GPU,擁有極為巨大的計算能力。這真的不能算是公平的比賽,就像李世石拿的是一把破菜刀而對手端著機關槍。但阿爾法圍棋獲勝的真正秘訣不是硬體,我個人的看法,是在於蒙特卡洛樹搜索(Monte-Carlo Tree Search)的演算法。正是這個演算法,使得程序具有了自我學習的能力,並且能有效地控制搜索的複雜性。
白露為霜注:AlphaGo最終以4:1獲勝。李世石戰的很英勇,雖敗猶榮。
阿爾法圍棋:使用機器學習掌握古老的圍棋
AlphaGo: Mastering the ancient game of Go with Machine Learning
遊戲是測試與人類解決問題方法相似更聰明,更靈活的演算法的一個很好的試驗場。人類很早就開始創造能比最出色的人玩遊戲玩的更好的程序 – 作為1952年一個博士生的畢業設計,計算機學會了第一個經典的遊戲 - 「玩圈和十字架」(noughts and crosses),也稱為tic-tac-toe。接著1994年計算機在跳棋(checkers)上打敗人類高手。IBM的「深藍」在1997年擊敗國際象棋大師Kasparov更是轟動一時。計算機的成功並不局限於棋類,IBM的「華生」(Waston)在2011年獲得Jeopardy的冠軍。僅根據原始象素的輸入,谷歌的演算法還學會了玩數十種Atari遊戲。
但有一種遊戲一直讓人工智慧的企圖遭受挫敗:古老的圍棋。2500年前發明於中國,目前世界範圍下圍棋的人數超過四千萬人。圍棋的規則很簡單:玩家輪流將黑色或白色的棋子放在棋盤上,試圖捕捉對手的棋子或者圍成空地而得分。孔子曾經寫過這個遊戲,它的美感讓它被提升到任何中國學者必需具備的四種技藝之一(註:琴棋書畫)。下圍棋主要靠直覺和感受,很多世紀以來一直因其精妙博大和思維的深度而讓人們著迷。
但儘管規則很簡單,圍棋其實是極為複雜的遊戲,圍棋的搜索空間是如此的巨大,是10的100次方倍大於國際象棋的搜索空間 - 這個數字比整個宇宙所有原子的總和還要大。其結果是,傳統的「蠻力」(brute force)人工智慧方法 - 構建一個所有可能的下法的搜索樹在圍棋上無法做到。迄今為止,電腦下圍棋的水平還是業餘級的。專家預測至少需要10年時間電腦才有可能擊敗頂級專業圍棋手。
我們認為這是一個難以拒絕的挑戰!我們開始構建一個系統,阿爾法圍棋(AlphaGo),來克服種種障礙。AlphaGo程序關鍵是將圍棋巨大的搜索空間減少到可以對付的規模。要做到這一點,它將最先進的樹搜索(tree search)方法同兩個深度神經網路相結合,每個神經網路包含很多層的數以百萬計的像神經元樣的聯結。一個神經網路稱為「策略網路」(policy network)用來預測下一步的行動,通過只考慮最有可能導致勝利的下法來縮小搜索範圍。另外一個神經網路叫「價值網路」(value network)用於減少搜索樹的深度 – 評估在走每一步贏的可能性,一路搜索到遊戲的結束。
AlphaGo的搜索演算法比以前的方法更接近人的思維方法。例如,當「深藍」下棋時,它使用比AlphaGo多數千倍的蠻力搜索。相反,AlphaGo使用一種稱為「蒙特卡洛樹搜索」(Monte-Carlo Tree Search)在它腦子中一遍又一遍地把剩下的棋下完。同以前的蒙特卡羅程序不同的是,AlphaGo使用深層神經網路來指導其搜索。在每個模擬遊戲中,策略網路建議最聰明的下法,而價值網路則精確地評估下完這步后局面的優劣。最後,AlphaGo選擇在模擬中最成功的下法。
我們首先使用從人類下的棋中的3千萬種常用走法來訓練策略網路,直到它可以以57%的準確度預測出人類的回應(AlphaGo前之前的紀錄是44%)。但是,我們的目標是擊敗最好的人類棋手,而不僅僅是模仿他們。要做到這一點,AlphaGo必須學會發現新的策略。通過在神經網路之間下數以千記的棋,並在一種被稱為「強化學習」一個試錯的過程中不斷改進。這種做法導致了更好的策略網路,這個網路是如此強大的,即使僅僅是沒有樹搜索的原始的神經網路就可以打敗最先進的建有龐大的搜索樹的程序。
這些策略網路再用來訓練價值網路,同樣是通過自我下棋來學習改進。這些價值網路可以評估任何圍棋的局面,並計算出最後的優勝者 – 這個任務非常的困難,以前一直被認為是不可能完成的問題。
當然,所有這些都需要巨大的計算能力,所以我們大量使用谷歌雲平台(Google Cloud Platform),這使得做人工智慧(AI)和機器學習(ML)的研究人員能按照需求彈性的運用計算、存儲和網路的能力。此外,用來數量計算的數據流圖的開源庫,如TensorFlow,使研究人員能夠高效地部署多個中央處理器(CPU)或圖像處理器(GPU)來滿足深度學習演算法的計算需要。
AlphaGo似乎做好了準備迎接更大的挑戰。所以我們邀請了三次歐洲圍棋冠軍樊麾 – 從12歲時起就投身圍棋的一個精英職業棋手,到我們在倫敦辦公室進行挑戰賽。這場比賽在去年10月5-9日之間進行。AlphaGo以5:0取勝 – 這是計算機程序第一次擊敗一個職業圍棋手。
AlphaGo的下一個挑戰將是在過去十年中一直處在世界顛峰的李世石。比賽在今年三月於韓國首爾舉行。李世石很高興接受挑戰說:「我很榮幸地下這場人機大戰,但我相信我能取勝。」這將被證明是一場引人入勝的比賽!
我們很高興已經學會了圍棋,從而完成了人工智慧的重大挑戰之一。然而,這一切對我們來說最有意義的是AlphaGo不僅僅手工編寫的規則,建立了一個「專家系統」,而是使用通用的機器學習的技術,通過觀看和自我下棋不斷完善自身。雖然遊戲是開發和快速高效地測試人工智慧演算法的完美平台,最終我們希望將這些技術應用於重要的現實問題上。因為我們所用的方法是通用的,我們希望有一天它們可以被擴展到幫助我們解決一些社會的最棘手和最緊迫的問題,從氣候建模到複雜的疾病分析。
英文原文:
AlphaGo: Mastering the ancient game of Go with Machine Learning
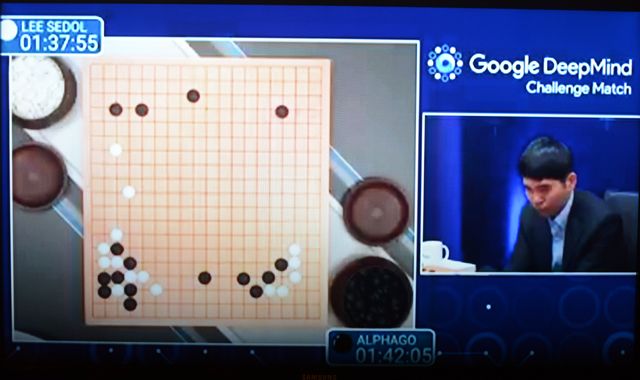
網路直播人機大戰第二局
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| First 99 moves |
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Moves 100-199 |
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Moves 200-211 |
- [01/04]沙漠秀影
- [01/19]假如我中了15億美元
- [02/01]國寶重現江湖:土山灣的驚艷
- [02/15]酒鄉記事:滿地盡披黃金甲
- [03/02]在蒙特利看王者歸來
- [03/11] 李世石堪堪要敗:人類快要沒戲了
- [03/22]極客們的狂歡:矽谷動漫節一瞥
- [04/02]特斯拉三型:昨天你土豪了嗎?
- [04/11]AlphaGo餘波:機器能夠取代人嗎?
- [05/03]矽谷的孩子課外都玩什麼?
- [05/11]舊金山「怪誕街會」一瞥
- [06/10]為什麼說週遊世界要趕早
- [06/23]「空中食宿」(Airbnb)是如何征服世界的
- 查看:[白露為霜的.最新博文]
- 查看:[大家的.最新博文]
- 查看:[大家的.留學生活]
發表評論 評論 (63 個評論)

- 回復 fanlaifuqu
- 那是敗在自己手下!

- 回復 borninheaven
- 電腦科技進步無限!戰勝圍棋高手非常不易,傳統的軟體窮盡演算法難以在圍棋中取勝,變化組合太多,電腦跟不上。那些電腦象棋遊戲很容易戰勝真人,但電腦圍棋遊戲基本上都是人贏,只要你稍有點圍棋經驗就贏了。

- 回復 xqw63
- 最近很熱的新聞,電腦戰勝人腦,這是一次絕好的宣傳,通過谷歌這樣的宣傳,圍棋將很快走入歐美,日本對圍棋的宣傳經過了幾十年,但圍棋一直在中日韓三個國家玩,谷歌的介入,從效果上來看,甚至超過了日本前幾十年的努力


- 回復 sissycampbell
- 我老公是圍棋迷,這兩天一直在議論這件事。我也覺得圍棋手有可能敗在自己手下。。


- 回復 白露為霜
- 也不能說是敗在自己手下。谷歌有的是工程師,並沒有職業級別的棋手,幾個臭皮匠居然能調教出個諸葛亮。其實工程師為電腦設計了個能夠自我學習的軟體,招法是這個軟體根據學別人棋譜和自己下棋學來的。
fanlaifuqu: 那是敗在自己手下!
- 回復 白露為霜
- 很有可能大勝,人越來越累,越來越沒信心,機器沒這問題。不出意外,AlphaGo應該能贏。李世石如果能扳回一盤就算給人類掙回點顏面。
泥馬: 謝謝翻譯介紹,大開眼界太牛了。如AlphaGo能大獲全勝,會是推動AI和ML深度發展應用的里程碑。加一句,這麼專業的翻譯也很牛啊。
- 回復 白露為霜
- 人工智慧近年有了長足的進步。早以不是當年吳下阿蒙了。
borninheaven: 電腦科技進步無限!戰勝圍棋高手非常不易,傳統的軟體窮盡演算法難以在圍棋中取勝,變化組合太多,電腦跟不上。那些電腦象棋遊戲很容易戰勝真人,但電腦圍棋遊戲基
- 回復 白露為霜
- 的確。看人機大賽的YOUTUBE的人已經快200萬了。不知道在北美還有這麼多人對圍棋感興趣。也許是對人工智慧感興趣。
xqw63: 最近很熱的新聞,電腦戰勝人腦,這是一次絕好的宣傳,通過谷歌這樣的宣傳,圍棋將很快走入歐美,日本對圍棋的宣傳經過了幾十年,但圍棋一直在中日韓三個國家玩,
- 回復 白露為霜
- 網上應該有跳棋可以下。跳棋比較簡單,人類在20年前就不是計算機的對手了。
嘻哈:): 天啊
 ,這計算機膩恐怖滴!俺不懂圍棋,連李世石是何許人以前都不知道
,這計算機膩恐怖滴!俺不懂圍棋,連李世石是何許人以前都不知道  。棋類俺好像就會跳棋,曾經也「無敵手」過 ,該也有跳棋程序了吧
。棋類俺好像就會跳棋,曾經也「無敵手」過 ,該也有跳棋程序了吧
白露為霜最受歡迎的博文
其它[留學生活]博文更多
- 嫣蝶:我在洛杉磯辛苦打工的那些日子 (上)
- 白露為霜:在蒙特利看王者歸來
- 嫣蝶:中餐館里的五花八門(下)
- 嫣蝶:中餐館里的五花八門(中)
- 嫣蝶:中餐館里的五花八門(上)
- 白露為霜:酒鄉記事:滿地盡披黃金甲
- 穿鞋的蜻蜓:這個「應該」在外國大學錄取的標準里,根本就不存在
- 白露為霜:國寶重現江湖:土山灣的驚艷
- qwxqwsean:從一個例子看美國大學生的生活狀態
- 白露為霜:假如我中了15億美元
- qwxqwsean:中國的大學辦不好因為沒有教學大綱
- 白露為霜:沙漠秀影
- 白露為霜:為什麼說兒女都是白眼狼?
- 心路獨舞:發財也難抵流浪的自由
- CCNews:聖誕節 加拿大也有窮人需要幫助
- 徐罡博士:留學美國,我的第一樁糗事
- 白露為霜:家有數學天才 如何是好?