|
|
定義 7 (坐標下降). 通過循環使用不同坐標方向,每次固定其他元素,只沿一個坐標方向進行優化,以達到目標函數的局部最小,見演演算法 1.
我們希望在支持向量機中的對偶型中,每次固定除 αi 外的其他變數,之後求在 αi 方向上的極值。但由於 約束,當其他變數固定時,αi 也隨著確定。這樣,我們無法在不違背約束的前提下對 αi 進行優化。因此,SMO 每步同時選擇兩個變數 αi 和 αj 進行優化,並固定其他參數,以保證不違背約束。

定理 32 (SMO 每步的優化目標). SMO 每步的優化目標為

推論 33. SMO 每步的優化目標可等價為對 αi 的單變數二次規劃問題。
證明. 由於,我們可以將其代入 SMO 每步的優化目標,以消去變數 αj。此時,優化目標函數是對於 αi 的二次函數,約束是一個取值區間 L ≤ αi ≤ H。之後根據目標函數頂點與區間 [L, H] 的位置關係,可以得到 αi 的最優值。理論上講,每步優化時 αi 和 αj 可以任意選擇,但實踐中通常取 αi 為違背 KKT 條件最大的變數,而 αj取對應樣本與 αi 對應樣本之間間隔最大的變數。對 SMO 演演算法收斂性的測試可以用過檢測是否滿足 KKT 條件得到。
6.2 Pegasos
我們也可以直接在原問題對支持向量機進行優化,尤其是使用線性核函數時,我們有很高效的優化演演算法,如 Pegasos [14]。Pegasos 使用基於梯度的方法在線性支持向量機基本型
進行優化,見演演算法 2。

6.3 近似演演算法
當使用非線性核函數下的支持向量機時,由於核矩陣,所以時間複雜度一定是,因此,有許多學者致力於研究一些快速的近似演演算法。例如,CVM [15]基於近似最小包圍球演演算法,Nyström 方法[18]通過從 K 採樣出一些列來得到 K 的低秩近似,隨機傅里葉特徵[12]構造了向低維空間的隨機映射。本章介紹了許多優化演演算法,實際上現在已有許多開源軟體包對這些演演算法有很好的實現,目前比較著名的有 LibLinear[7] 和 LibSVM[3],分別適用於線性和非線性核函數。
7. 支持向量機的其他變體
ProbSVM. 對數幾率回歸可以估計出樣本屬於正類的概率,而支持向量機只能判斷樣本屬於正類或負類,無法得到概率。ProbSVM[11]先訓練一個支持向量機,得到參數 (w, b)。再令,將當做新的訓練數據訓練一個對數幾率回歸模型,得到參數。因此,ProbSVM 的假設函數為
對數幾率回歸模型可以認為是對訓練得到的支持向量機的微調,包括尺度 (對應 θ1) 和平移 (對應 θ0)。通常 θ1 > 0,θ0 ≈ 0。
多分類支持向量機. 支持向量機也可以擴展到多分類問題中. 對於 K 分類問題,多分類支持向量機 [17] 有 K 組參數,並希望模型對於屬於正確標記的結果以 1 的間隔高於其他類的結 果,形式化如下


References
[1] B. E. Boser, I. M. Guyon, and V. N. Vapnik. A training algorithm for optimal margin classifiers. In Proceedings of the Annual Workshop on Computational Learning Theory, pages 144–152, 1992. 5
[2] S. Boyd and L. Vandenberghe. Convex optimization. Cambridge university press, 2004. 4
[3] C.-C. Chang and C.-J. Lin. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2(3):27, 2011. 10
[4] C. Cortes and V. Vapnik. Support-vector networks. Machine Learning, 20(3):273–297, 1995. 1 [5] N. Cristianini and J. Shawe-Taylor. An introduction to support vector machines and other kernel-based learning methods. Cambridge University Press, 2000. 6
[6] H. Drucker, C. J. Burges, L. Kaufman, A. J. Smola, and V. Vapnik. Support vector regression machines. In Advances in Neural Information Processing Systems, pages 155–161, 1997. 10
[7] R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C.-J. Lin. LIBLINEAR: A library for large linear classification. Journal of Machine Learning Research, 9(8):1871–1874, 2008. 10
[8] T. Hofmann, B. Schölkopf, and A. J. Smola. Kernel methods in machine learning. The Annals of Statistics, pages 1171–1220, 2008. 6
[9] G. R. Lanckriet, N. Cristianini, P. Bartlett, L. E. Ghaoui, and M. I. Jordan. Learning the kernel matrix with semidefinite programming. Journal of Machine Learning Research, 5(1):27–72, 2004. 6 [10] J. Platt. Sequential minimal optimization: A fast algorithm for training support vector machines. Micriosoft Research, 1998. 9
[11] J. Platt et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in Large Margin Classifiers, 10(3):61–74, 1999. 10
[12] A. Rahimi and B. Recht. Random features for largescale kernel machines. In Advances in Neural Information Processing Systems, pages 1177–1184, 2008. 10
[13] B. Scholkopf and A. J. Smola. Learning with kernels: support vector machines, regularization, optimization, and beyond. MIT press, 2001. 6
[14] S. Shalev-Shwartz, Y. Singer, N. Srebro, and A. Cotter. Pegasos: Primal estimated sub-gradient solver for SVM. Mathematical Programming, 127(1):3–30, 2011. 9
[15] I. W. Tsang, J. T. Kwok, and P.-M. Cheung. Core vector machines: Fast SVM training on very large data sets. Journal of Machine Learning Research, 6(4):363– 392, 2005. 10
[16] V. Vapnik. The nature of statistical learning theory. Springer Science & Business Media, 2013. 5
[17] J. Weston, C. Watkins, et al. Support vector machines for multi-class pattern recognition. In Proceedings of the European Symposium on Artificial Neural Networks, volume 99, pages 219–224, 1999. 10
[18] C. K. Williams and M. Seeger. Using the nyström method to speed up kernel machines. In Advances in Neural Information Processing Systems, pages 682–688, 2001. 10
[19] 周志華. 機器學習. 清華大學出版社, 2016. 9
|
|





 狗仔卡
狗仔卡








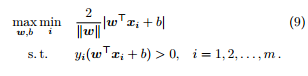


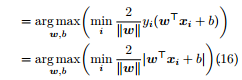










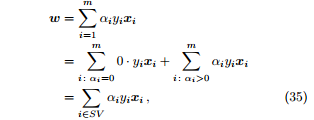



















 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 搶沙發
搶沙發 樓主
樓主