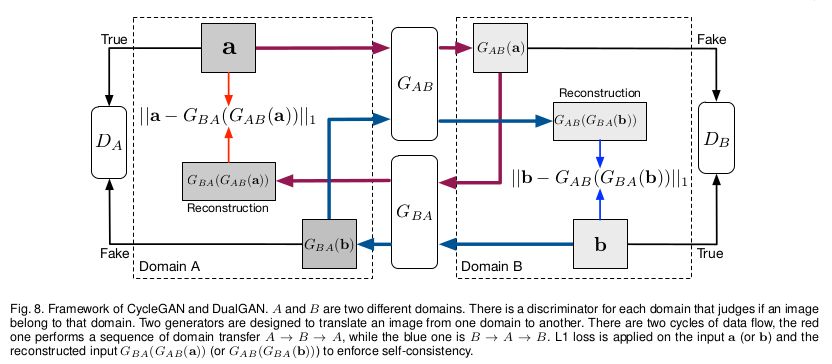
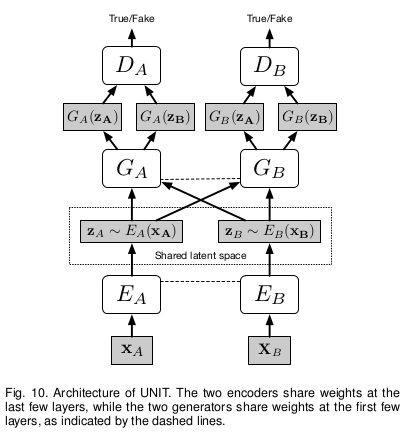
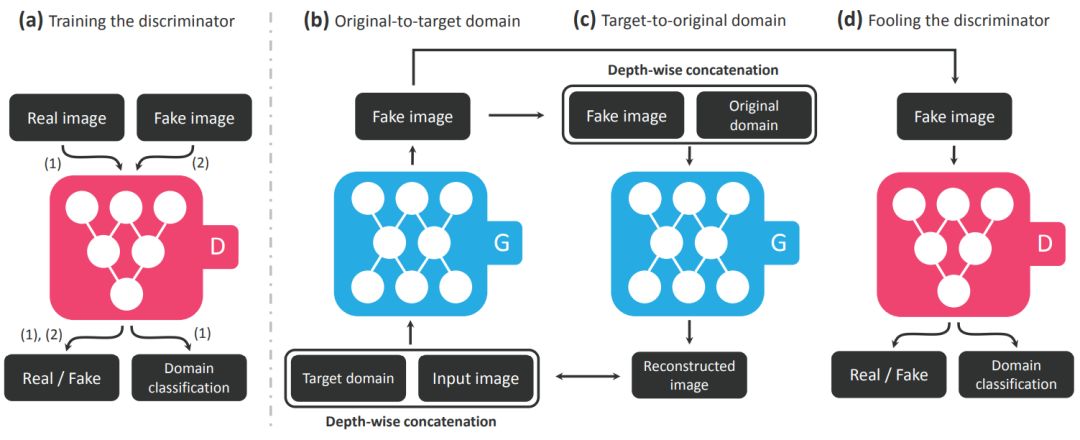
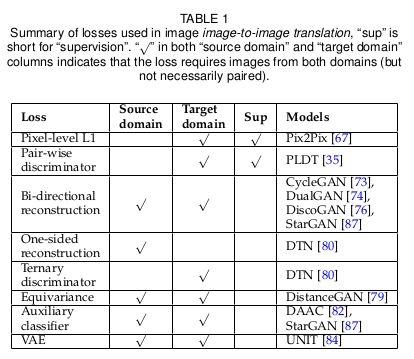
|
|
Fréchet Inception Distance (FID) [39]提供了一種不同的方法。首先,生成的圖像嵌入到初始網路的所選層的潛在特徵空間中。其次,將生成的和真實的圖像的嵌入視為來自兩個連續多元高斯的樣本,以便可以計算它們的均值和協方差。然後,生成的圖像的質量可以通過兩個高斯之間的 Fréchet 距離來確定:

上式 (μx,μg) 和 (∑x,∑g) 分別是來自真實數據分佈和生成樣本的均值和協方差。FID 與人類判斷一致,並且 FID 與生成圖像的質量之間存在強烈的負相關。此外,FID 對雜訊的敏感度低於 IS,並且可以檢測到類內模式崩潰。
總結
本文在論文 An Introduction to Image Synthesis with Generative Adversarial Nets的基礎上回顧了 GAN 的基礎知識、圖像生成方法的三種主要方法,即直接方法,分層方法和迭代方法和其它生成方法,如迭代採樣。也討論了圖像合成的兩種主要形式,即文本到圖像合成和圖像到圖像的轉換。
希望本文可以幫助讀者理清 GAN 在圖像生成方向的指導,當然限於原論文(本文多數內容為翻譯原文),還有很多篇精彩的 GAN 在圖像生成方向的論文沒有涉及,讀者可以自行閱讀。
參考文獻
[1] Kingma D P, Welling M. Auto-encoding variational bayes[J]. arXiv preprint arXiv:1312.6114, 2013.
[2] van den Oord, Aaron, et al. 「Conditional image generation with pixelcnn decoders.」 Advances in Neural Information Processing Systems. 2016.
[3] Kingma, Durk P., and Prafulla Dhariwal. 「Glow: Generative flow with invertible 1x1 convolutions.」 Advances in Neural Information Processing Systems. 2018.
[4] Goodfellow, Ian, et al. 「Generative adversarial nets.」 Advances in neural information processing systems. 2014.
[5] A. Radford, L. Metz, and S. Chintala, 「Unsupervised represetation learning with deep convolutional generative adversarial networks,」 arXiv preprint arXiv:1511.06434, 2015.
[6] M. Mirza and S. Osindero, 「Conditional generative adversarial nets,」arXiv preprint arXiv:1411.1784, 2014.
[7] A. Odena, C. Olah, and J. Shlens, 「Conditional image synthesis with auxiliary classifier gans,」 arXiv preprint arXiv:1610.09585,2016.
[8] J. Donahue, P. Krähenbühl, and T. Darrell, 「Adversarial feature learning,」 arXiv preprint arXiv:1605.09782, 2016.
[9] V. Dumoulin, I. Belghazi, B. Poole, A. Lamb, M. Arjovsky, O. Mastropietro, and A. Courville, 「Adversarially learned inference,」arXiv preprint arXiv:1606.00704, 2016.
[10] A. B. L. Larsen, S. K. Sønderby, H. Larochelle, and O. Winther,「Autoencoding beyond pixels using a learned similarity metric,」arXiv preprint arXiv:1512.09300, 2015.
[11] T. Che, Y. Li, A. P. Jacob, Y. Bengio, and W. Li, 「Mode regularized generative adversarial networks,」 arXiv preprint arXiv:1612.02136, 2016.
[12] M. Arjovsky, S. Chintala, and L. Bottou, 「Wasserstein gan,」 arXiv preprint arXiv:1701.07875, 2017.
[13] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. Courville, 「Improved training of wasserstein gan,」 arXiv preprint arXiv:1704.00028, 2017.
[14] Miyato, Takeru, et al. 「Spectral normalization for generative adversarial networks.」 arXiv preprint arXiv:1802.05957 (2018).
[15] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford,and X. Chen, 「Improved techniques for training gans,」 in Advances in Neural Information Processing Systems, 2016, pp. 2226–2234.
[16] X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel, 「Infogan: Interpretable representation learning by information maximizing generative adversarial nets,」 in Advances In Neural Information Processing Systems, 2016, pp. 2172–2180.
[17] S. Nowozin, B. Cseke, and R. Tomioka, 「f-gan: Training generative neural samplers using variational divergence minimization,」arXiv preprint arXiv:1606.00709, 2016.
[18] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee,「Generative adversarial text to image synthesis,」 arXiv preprint arXiv:1605.05396, 2016.
[19] X. Wang and A. Gupta, 「Generative image modeling using style and structure adversarial networks,」 arXiv preprint arXiv:1603.05631, 2016.
[20] E. L. Denton, S. Chintala, a. szlam, and R. Fergus, 「Deep generative image models using a laplacian pyramid of adversarial networks,」 in Advances in Neural Information Processing Systems Curran Associates, Inc., 2015, pp. 1486–1494.
[21] H. Zhang, T. Xu, H. Li, S. Zhang, X. Huang, X. Wang, and D. Metaxas, 「Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks,」 arXiv preprint arXiv:1612.03242, 2016.
[22] X. Huang, Y. Li, O. Poursaeed, J. Hopcroft, and S. Belongie, 「Stacked generative adversarial networks,」 arXiv preprint arXiv:1612.04357, 2016.
[23] A. Nguyen, J. Yosinski, Y. Bengio, A. Dosovitskiy, and J. Clune,「Plug & play generative networks: Conditional iterative generation of images in latent space,」 arXiv preprint arXiv:1612.00005,2016.
[24] T. Karras, T. Aila, S. Laine, and J. Lehtinen, 「Progressive growing of gans for improved quality, stability, and variation,」 arXiv preprint arXiv:1710.10196, 2017.
[25] A. Dash, J. C. B. Gamboa, S. Ahmed, M. Z. Afzal, and M. Liwicki,「Tac-gan-text conditioned auxiliary classifier generative adversarial network,」 arXiv preprint arXiv:1703.06412, 2017.
[26] S. E. Reed, Z. Akata, S. Mohan, S. Tenka, B. Schiele, and H. Lee,「Learning what and where to draw,」 in Advances in Neural Information Processing Systems, 2016, pp. 217–225.
[27] H. Zhang, T. Xu, H. Li, S. Zhang, X. Wang, X. Huang, and D. N. Metaxas, 「Stackgan++: Realistic image synthesis with stacked generative adversarial networks,」 CoRR, vol. abs/1710.10916,2017.
[28] T. Xu, P. Zhang, Q. Huang, H. Zhang, Z. Gan, X. Huang, andX. He, 「Attngan: Fine-grained text to image generation with attentional generative adversarial networks,」 arXiv preprint arXiv:1711.10485, 2017.
[29] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, 「Image-to-image translation with conditional adversarial networks,」 arXiv preprint arXiv:1611.07004, 2016.
[30] D. Yoo, N. Kim, S. Park, A. S. Paek, and I. S. Kweon, 「Pixel-level domain transfer,」 in European Conference on Computer Vision. Springer, 2016, pp. 517–532.
[31] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, 「Unpaired image-to-image translation using cycle-consistent adversarial networks,」arXiv preprint arXiv:1703.10593, 2017.
[32] Z. Yi, H. Zhang, P. T. Gong et al., 「Dualgan: Unsupervised dual learning for image-to-image translation,」 arXiv preprint arXiv:1704.02510, 2017.
[33] T. Kim, M. Cha, H. Kim, J. Lee, and J. Kim, 「Learning to discover cross-domain relations with generative adversarial networks,」arXiv preprint arXiv:1703.05192, 2017.
[34] S. Benaim and L. Wolf, 「One-sided unsupervised domain mapping,」 arXiv preprint arXiv:1706.00826, 2017.
[35] Y. Taigman, A. Polyak, and L. Wolf, 「Unsupervised cross-domain image generation,」 arXiv preprint arXiv:1611.02200, 2016.
[36] neural information processing systems, 2014, pp. 2366–2374.M.-Y. Liu, T. Breuel, and J. Kautz, 「Unsupervised image-to-image translation networks,」 in Advances in Neural Information Processing Systems, 2017, pp. 700–708.
[37] M.-Y. Liu and O. Tuzel, 「Coupled generative adversarial networks,」 in Advances in neural information processing systems, 2016,pp. 469–477.
[38] Y. Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo, 「StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation,」 arXiv preprint arXiv:1711.09020,2017.
[39] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, G. Klambauer, and S. Hochreiter, 「Gans trained by a two time-scale update rule converge to a nash equilibrium,」 CoRR, vol. abs/1706.08500, 2017.
[40] Huang, He, Phillip S. Yu, and Changhu Wang. 「An Introduction to Image Synthesis with Generative Adversarial Nets.」 arXiv preprint arXiv:1803.04469 (2018).
[41] http://www.twistedwg.com/2018/01/30/GAN-problem.html
[42] https://www.paperweekly.site/papers/notes/503
本文由 AI 學術社區 PaperWeekly 精選推薦,社區目前已覆蓋自然語言處理、計算機視覺、人工智慧、機器學習、數據挖掘和信息檢索等研究方向,點擊「閱讀原文」即刻加入社區!
|
|





 狗仔卡
狗仔卡








 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 搶沙發
搶沙發 樓主
樓主